ǰ��
�������ҽ��ܵ���Python������������������վͼƬ���ݣ����������Ҫ��С����Ǵ��룬���Ҹ���һ��С�ĵá�
��������ȡ֮ǰӦ�þ�����αװ�������������ʶ����������棬�������Ǽ�����ͷ�����������Ĵ��ı�������ȡ���˻�ܶ࣬����������Ҫ���Ǹ�������IP�������������ͷ�ķ�ʽ����������վͼƬ���ݽ�����ȡ��
��ÿ�ν����������ı�д֮ǰ�����ǵĵ�һ��Ҳ������Ҫ��һ�����Ƿ������ǵ���ҳ��
ͨ���������Ƿ�������ȡ�������ٶȱȽ������������ǻ�����ͨ�����ùȸ������ͼƬ��java script�ȷ�ʽ����������ȡ�ٶȡ�
��������
Python�汾�� 3.6
���ģ�飺
requestsģ��
parselģ��
reģ��
�����
��װPython�����ӵ�����������pip��װ��Ҫ�����ģ�鼴�ɡ�
�����������뼰�ļ����������Ի�ȡ
������Դ��ѯ����
������д�����Ҫ��ȡ��ҳ��
��F12���뿪���߹��ߣ��鿴������Ҫ��������վͼƬ����������
����������Ҫҳ�����ݾͿ�����

����ʵ��
for page in range(1, 11):
# ��������
url = f'https://love.19lou.com/valueApp/api/love/searchLoveUser?page={page}&perPage=12&sex=0'
# αװģ��
headers = {
# User-Agent �û�����, ��ʾ�����������Ϣ
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
'Cookie':'���Cookie'
}
# ��������
response = requests.get(url=url, headers=headers)
print(response)
#forѭ������, ���б�����Ԫ��һ��һ����ȡ����
for index in response.json()['data']['items']:
# https://love.19lou.com/detail/51593564 format �ַ�����ʽ������
link = f'https://love.19lou.com/detail/{index["uid"]}'
html_data = requests.get(url=link, headers=headers).text
# �ѻ�ȡ���� html�ַ�������<html_data>, ת�ɿɽ�������
selector = parsel.Selector(html_data)
name = selector.css('.username::text').get()
info_list = selector.css('.info-tag::text').getall()
# . ��ʾ���÷�������
gender = info_list[0].split('��')[-1]
age = info_list[1].split('��')[-1]
height = info_list[2].split('��')[-1]
date = info_list[-1].split('��')[-1]
# �ж�info_listԪ�ظ��� ��Ԫ�ظ���4�� ˵��û������һ��
if len(info_list) == 4:
weight = '0kg'
else:
weight = info_list[3].split('��')[-1]
info_list_1 = selector.css('.basic-item span::text').getall()[2:]
zodiac = info_list_1[0].split('��')[-1]
constellation = info_list_1[1].split('��')[-1]
nativePlace = info_list_1[2].split('��')[-1]
location = info_list_1[3].split('��')[-1]
edu = info_list_1[4].split('��')[-1]
maritalStatus = info_list_1[5].split('��')[-1]
job = info_list_1[6].split('��')[-1]
money = info_list_1[7].split('��')[-1]
house = info_list_1[8].split('��')[-1]
car = info_list_1[9].split('��')[-1]
img_url = selector.css('.page .left-detail .abstract .avatar img::attr(src)').get()
# �ѻ�ȡ���������� �����ֵ����� �ֵ���������
dit = {
'�dz�': name,
'�Ա�': gender,
'����': age,
'����': height,
'����': weight,
'��������': date,
'��Ф': zodiac,
'����': constellation,
'����': nativePlace,
'���ڵ�': location,
'ѧ��': edu,
'����״��': maritalStatus,
'ְҵ': job,
'������': money,
'ס��': house,
'����': car,
'��Ƭ': img_url,
'����ҳ': link,
}
csv_writer.writerow(dit)
new_name = re.sub(r'[\/"*?<>|]', '', name)
��ȡCookie

Ч��չʾ
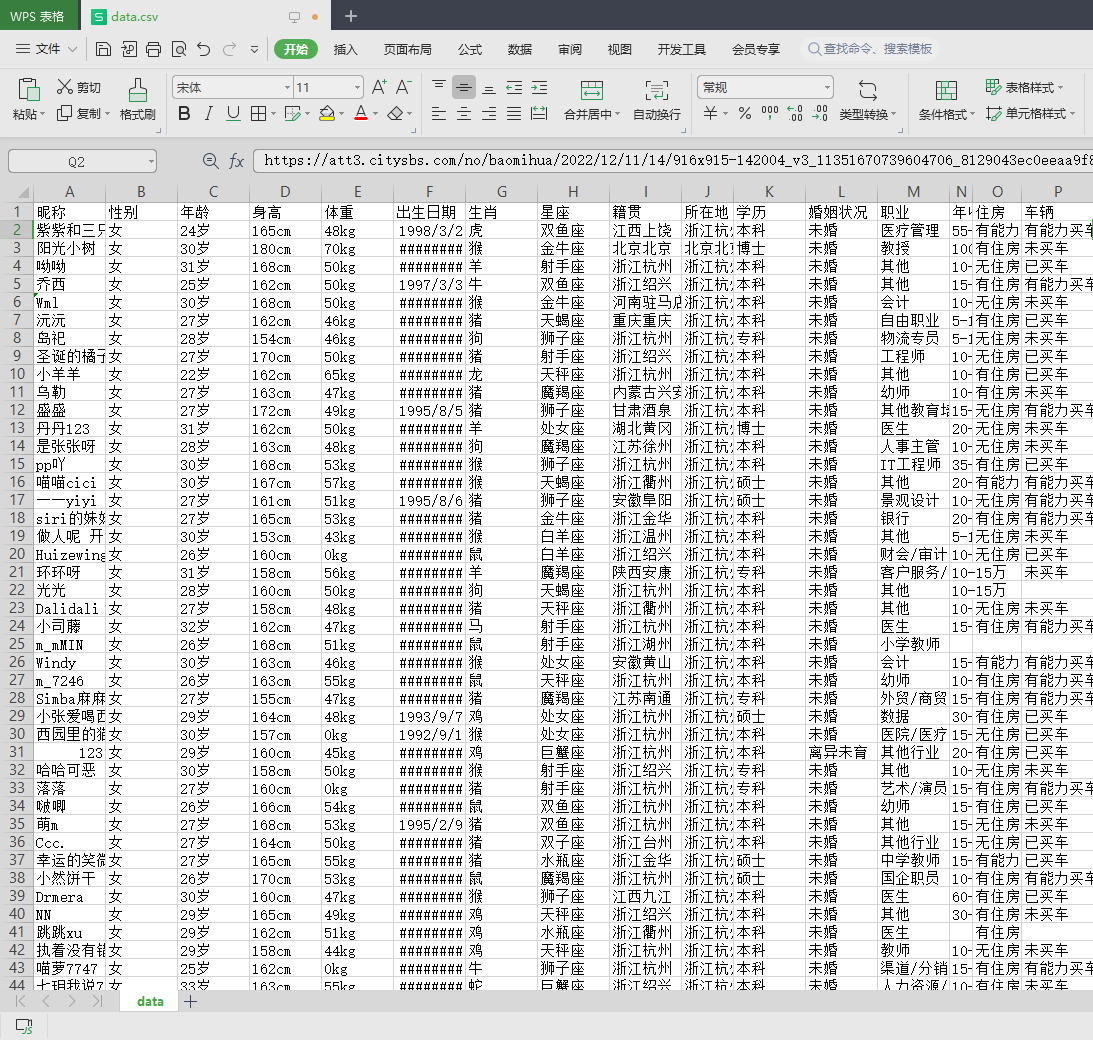
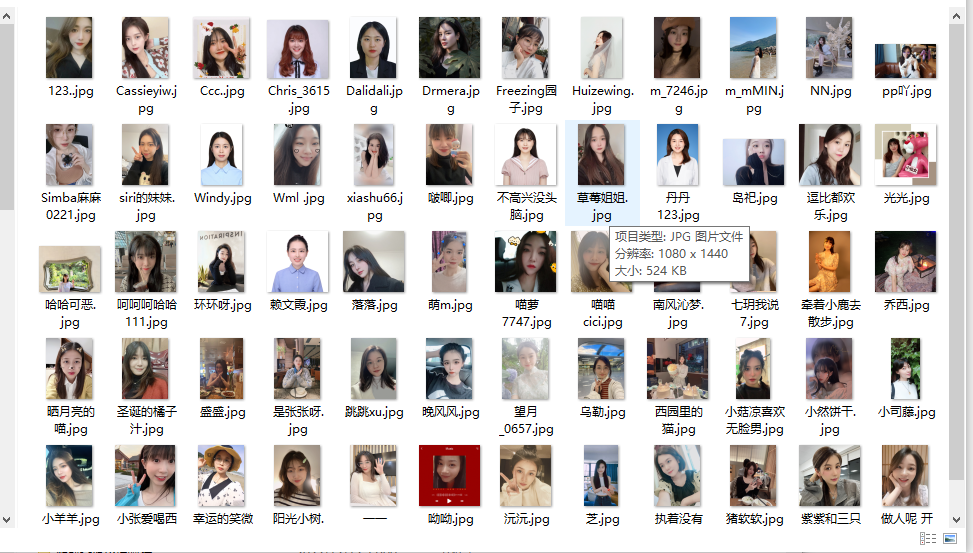
���
����ķ���������ͽ����� ������Ȥ������Ҳ����ȥ���Թ�
������������ģ���������������python�����⣬���������������Ի���˽����Ŷ
�����ҷ��������²����Ļ������Թ�עһ���ң����߸����µ���(/�R���Q)/