个待插入数据就被插入进了Dictionary中,这里总结一下Dictionary中插入一个数据要进行的步骤:
- 计算待插入数据键的HashCode值
- 将HashCode映射到Hash桶中,int index = HashCode % _buckets.length
- 在_entries数组的空闲处(即count或freelist下标处)“创建”一个包装好插入数据的Entry对象。(这里不是说真创建了一个对象,而是将那个位置的Entry属性的key,hashCode,value值改为待插入数据的属性)
- _buckets[index] 指向 _entries[count]处,插入完成
上面步骤对应的源码部分如下:
private bool TryInsert(TKey key, TValue value, InsertionBehavior behavior)
{
....
// 找到hashcode对应的Hash桶的位置
ref int bucket = ref _buckets[hashCode % _buckets.Length];
....
// 获得当前数组中的空闲位置
int count = _count;
// 如果位置不够,那么扩容
if (count == entries.Length)
{
Resize();
bucket = ref _buckets[hashCode % _buckets.Length];
}
index = count;
_count = count + 1;
entries = _entries;
....
// 目标Entry
ref Entry entry = ref entries[index];
....
// 将该处空闲的Entry的属性改完插入数据的属性
entry.hashCode = hashCode;
// Value in _buckets is 1-based
entry.next = bucket - 1;
entry.key = key;
entry.value = value;
// Value in _buckets is 1-based
bucket = index + 1;
_version++;
....
}
在前面插入的步骤中,我们可以看到内部变量freeList和freeCount并没有发生变动,这是因为他们是跟删除操作(remove)息息相关的,后面讲讲。
效率分析
根据上面的操作,可以看出Dictionary中,插入一个数据的时间是常数时间,即时间复杂度O(1)。
字典中的Find方法实现细节与效率分析
以上面插入完三个数据的Dictionary为例,下面讲讲Find方法的实现细节和效率。
该Dictionary的内部结构如下所示:
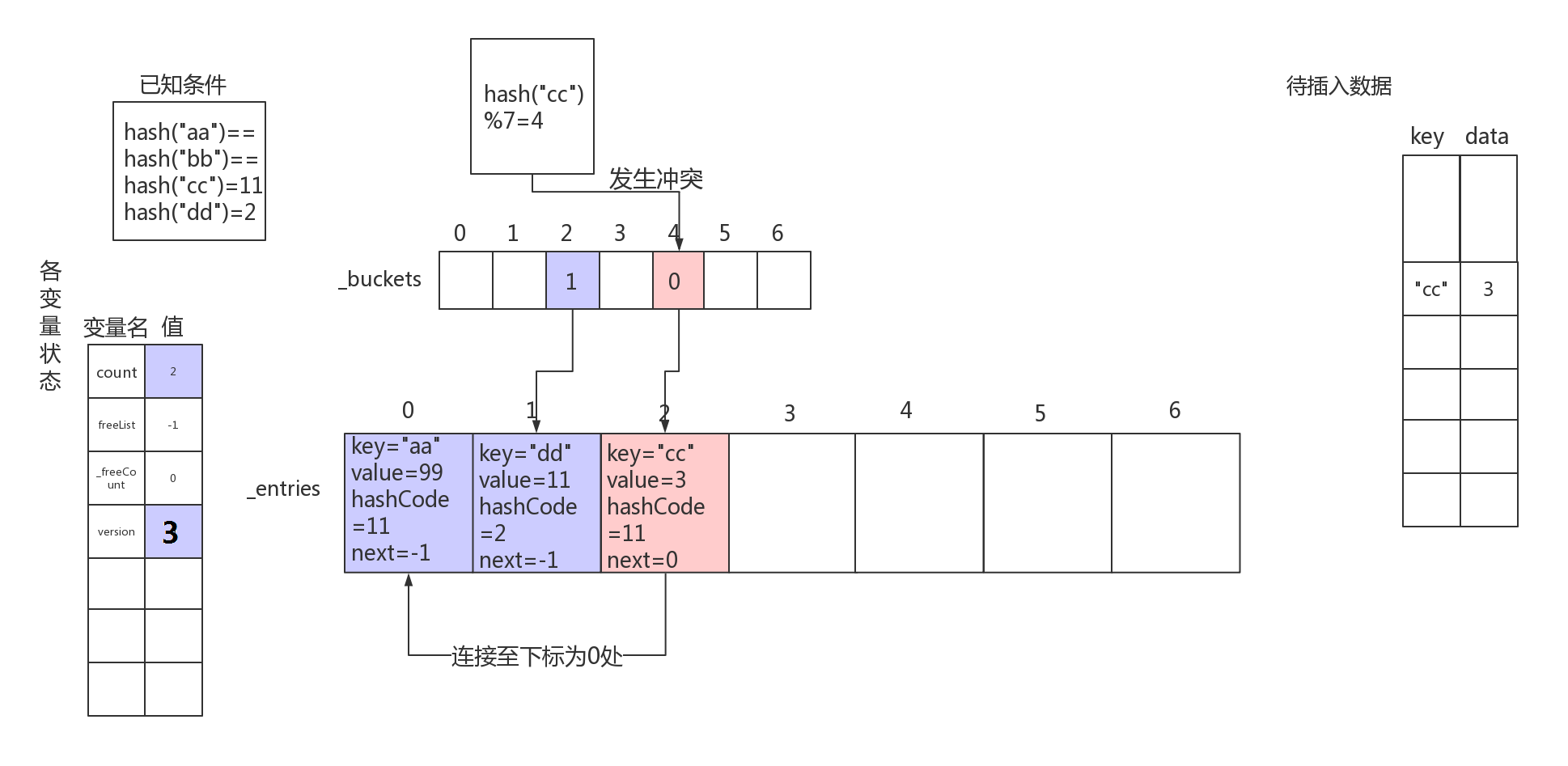
假设现在我们执行类似
map["aa"]
的操作,要获取键为"aa"存储的数据,会经过如下步骤:
- 计算key的Hash值,并算出在Hash桶的位置,即 hash("aa") % length
- 到达该Hash桶后,沿着这个Entry的next方法一路用"aa" == entry.key?比较过去。这里表达的意思是,一直沿着这个单链表向前找,直到找到key值相同的Entry,那么这个Entry保存的数据就是我们要找的值。
在Dictionary中还有一个常见的方法是GetValueOrDefault(),这个方法与上面步骤不同的地方是当沿着单链表一直找不到对应键值且entry.next==-1时,就会返回默认值。
效率分析
根据以上操作,很显然查找时间也是常数时间,也就是时间复杂度O(1),但是这个时间会随着Dictionary内部冲突的变多而增大,当所有元素冲突到一起时,每次查找都要消耗O(N)的时间。
为了解决这个问题,Dictionary内部会在合适的时候进行扩容并更换Hash函数。
字典中的Remove方法实现细节与效率分析
老实说我比较少用到字典的Remove方法额(汗颜),关于Remove方法,前面的步骤和查找是类似的。即先找到当前数据对应的Hash桶位置(不如说增删改查中查是最核心的,因为增删改第一个操作都是查)。
后面的步骤的执行如下带注释的代码所示。(代码引用自@InCerry的博文《浅析C# Dictionary实现原理》)
public bool Remove(TKey key) {
if(key == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null) {
// 1. 通过key获取hashCode
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
// 2. 取余获取bucket位置
int bucket = hashCode % buckets.Length;
// last用于确定是否当前bucket的单链表中最后一个元素
int last = -1;
// 3. 遍历bucket对应的单链表
for (int i = buckets[bucket]; i >= 0; last = i, i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
// 4. 找到元素后,如果last< 0,代表当前是bucket中最后一个元素,那么直接让bucket内下标赋值为 entries[i].next即可
if (last < 0) {
buckets[bucket] = entries[i].next;
}
else {
// 4.1 last不小于0,代表当前元素处于bucket单链表中间位置,需要将该元素的头结点和尾节点相连起来,防止链表中断
entries[last].next = entries[i].next;
}
// 5. 将Entry结构体内数据初始化
entries[i].hashCode = -1;
// 5.1 建立freeList单链表
entries[i].next = freeList;
entries[i].key = default(TKey);
entries[i].value = default(TValue);
// *6. 关键的代码,freeList等于当前的entry位置,下一次Add元素会优先Add到该位置
freeList = i;
freeCount++;
// 7. 版本号+1
version++;
return true;
}
}
}
return false;
}
总结一下,删除操作就是如下步骤:
- 找到目标Entry
- 将Entry初始化(HashCode初始化为-1)
- 将这个空闲的Entry(因为数据被删了,所以空闲)插入到Dictionary内部维护的freeList单链表中(entries[i].next=freeList这一句),等待下一次插入数据时,先找到这个freeList中的Entry来插。
效率分析
根据上面代码所示,Remove操作主要消耗时间的还是查找这一块,它的时间复杂度和查找相同,为O(1),但随着冲突的增多查找时间会逐渐加大。
字典