树重建,消耗更多性能。
根据要使用的HashMap大小确定初始容量,这也不是说为了避免扩容初始容量给的越大越好, 越大申请的内存就越大,如果你没有这么多数据去存,又会造成hash值过于离散,增加查询或修改的时间复杂度。
5.4 HashMap如何保证容量始终是2的幂?
HashMap使用方法tableSizeFor()来保证无论你给值是什么,返回的一定是2的幂
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
5.5 HashMap为何要保证容量始终是2的幂
- HashMap在定位元素在数组的index时,运算公式是 (n-1)&hash ,n为数组的长度。如果容量始终是2的次幂,例如 0000 0000 0000 0000 0000 0000 1000 0000,则n-1的二进制形式为:0000 0000 0000 0000 0000 0000 0111 1111 ,低位区一定是1,在进行 (n-1)&hash,hash低位区的0、1特征能够保留
- 因此,容量始终是2的幂,这样 下标index值的取值范围更广,减少hash碰撞。
5.6 HashMap计算hash值
1、带着疑问:
key的hashCode为什么右移16位后再进行异或运算?
2、关于 | & ^ 三种运算的特征说明:
- ^按位异或运算:位相同返回0,不同返回1;可推导出:任何数跟0异或返回任何数,任何数跟1异或返回对应的取反
- 异或运算能更好的保留各部分的特征,如果采用逻辑与&运算计算出来的值会向0靠拢(00得0,01得0,11得1 因此0的概率2/3),采用逻辑或|运算计算出来的值会向1靠拢 (00得0,01得1,11得1,因此1的概率为2/3)
3、hash()源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//key.hashCode() ;hashCode是Object对象的一个native方法,由操作系统实现,跟内存地址存在某种映射关系
4、进入分析:
5.6.1 key的hash值>>>16,为什么要这样做呢?
- h值右移16后,高16位都为0,这样h^(h>>>16)时,高16位的值不会有任何变化,但是低16位的值混杂了key的高16位的值,从而增加了hash值的复杂度,进一步减少了hash值一样的概率。
- 计算数组下标公式:(n-1)&hash,n-1的结果:高位趋于0;&运算的结果:高16位向0靠拢,hash的高位特征丢失
- 因此,如果我们不做hash值的移位和异或运算,那么在计算数组index时将丢失高区特征
简单点:
因为:(n-1)&hash中,hash的高位数将被数组长度的二进制码锁屏蔽,为确保hash的高位尽可能利用,就先对hash值先右移16位,再跟原hash值进行异或运算,同时保留高位和低位特征。
数组长度二进制码屏蔽是什么意思?
数组长度的数据类型int转化为32位的二进制,因为长度值对比最大值(2的32位)总是比较小的,所以它的高位趋向0,与其他数进行&运算后,结果值的高位趋向0,那么其他数的高位特征就丢失了
下面用例子分析:
### 计算hash
hashCode: 0000 0000 0101 0000 0000 0000 1111 1010
hashCode>>>16: 0000 0000 0000 0000 0000 0000 0101 0000
hashCode^hashCode>>>16: 0000 0000 0101 0000 0000 0000 0110 1010
hash=hashCode^hashCode>>>16 0000 0000 0101 0000 0000 0000 0110 1010
### 计算index时:
(n-1) (假设n=16) 0000 0000 0000 0000 0000 0000 0000 1111
(n-1)&hash 0000 0000 0000 0000 0000 0000 0000 1010
仔细观察上文不难发现,高16位很有可能会被数组长度的二进制码锁屏蔽,
如果我们不做移位异或运算,那么在计算数组index时将丢失高区特征

5.7 HashMap为什么是线程不安全的?
- 它没有任何的锁或者同步等多线程处理机制,无法控制并发下导致的线程冲突。
- 如果想要线程安全的使用基于hash表的map,可以使用ConcurrentHashMap,该实现get操作是无锁的,put操作也是分段锁,性能很好
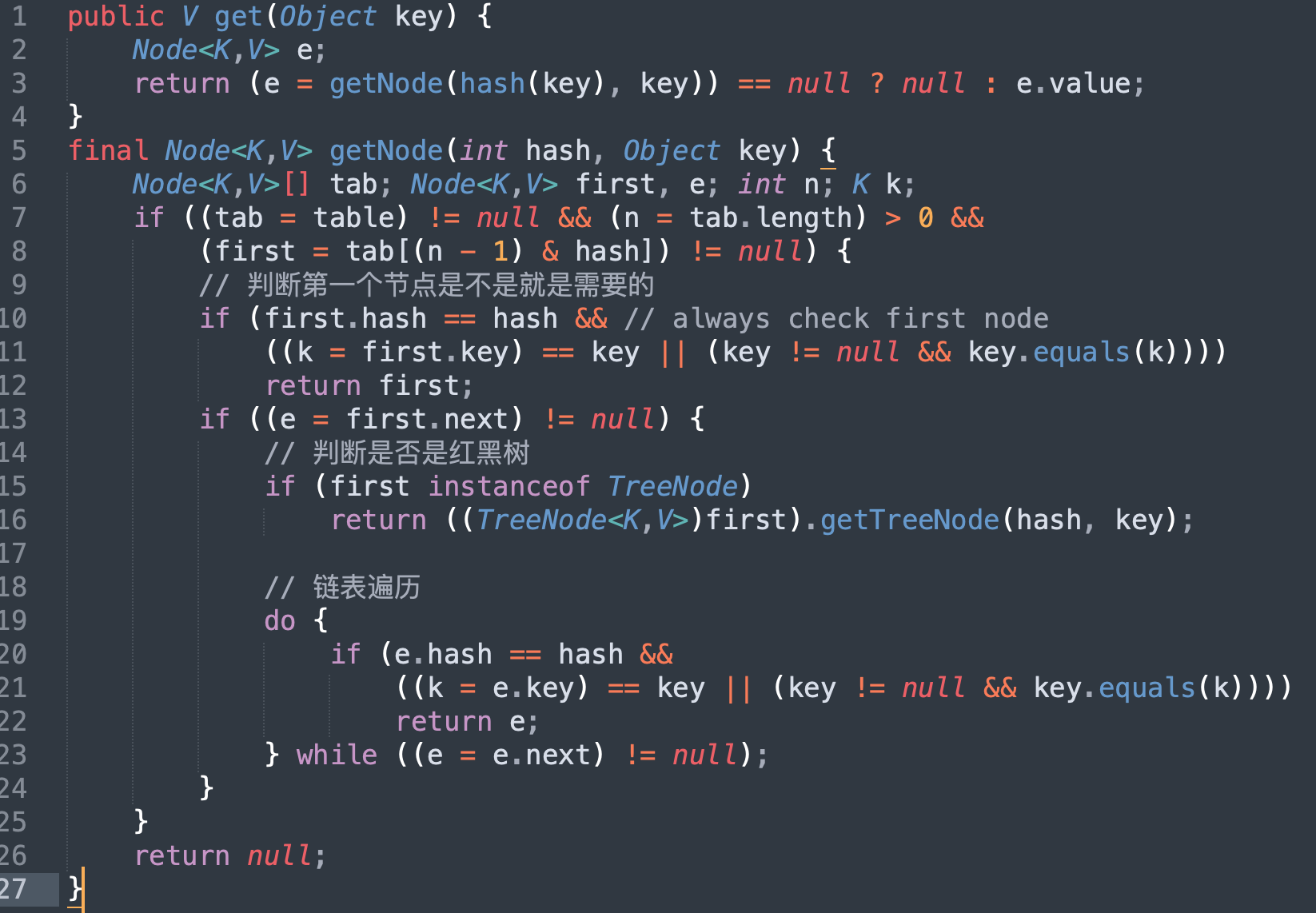
6 get 过程分析
- 计算 key 的 hash 值,根据 hash 值找到对应数组下标: hash & (length-1)
- 判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步
- 判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步
- 遍历链表,直到找到相等(==或equals)的 key
参考资料:
- [良许-HashMap源码实现分析]:https://www.cnblogs.com/yychuyu/p/13357218.html