ghgui/highgui.hpp>
// boost库中计时函数
#include <boost/timer.hpp>
// OpenGL
#include <GL/gl.h>
using namespace std;
int main( int argc, char** argv)
{
//声明SiftGPU并初始化
SiftGPU sift;
char* myargv[4] ={ "-fo", "-1", "-v", "1"};
sift.ParseParam(4, myargv);
//检查硬件是否支持SiftGPU
int support = sift.CreateContextGL();
if ( support != SiftGPU::SIFTGPU_FULL_SUPPORTED )
{
cerr<<"SiftGPU is not supported!"<<endl;
return 2;
}
//测试直接读取一张图像
cout<<"running sift"<<endl;
boost::timer timer;
//在此填入你想测试的图像的路径!不要用我的路径!不要用我的路径!不要用我的路径!
sift.RunSIFT( "/home/yao/workspace/SIFT_detection/image/1.png" );
cout<<"siftgpu::runsift() cost time="<<timer.elapsed()<<endl;
// 获取关键点与描述子
int num = sift.GetFeatureNum();
cout<<"Feature number="<<num<<endl;
vector<float> descriptors(128*num);
vector<SiftGPU::SiftKeypoint> keys(num);
timer.restart();
sift.GetFeatureVector(&keys[0], &descriptors[0]);
cout<<"siftgpu::getFeatureVector() cost time="<<timer.elapsed()<<endl;
// 先用OpenCV读取一个图像,然后调用SiftGPU提取特征
cv::Mat img = cv::imread("/home/yao/workspace/SIFT_detection/image/1.png", 0);
int width = img.cols;
int height = img.rows;
timer.restart();
// 注意我们处理的是灰度图,故照如下设置
sift.RunSIFT(width, height, img.data, GL_INTENSITY8, GL_UNSIGNED_BYTE);
cout<<"siftgpu::runSIFT() cost time="<<timer.elapsed()<<endl;
return 0;
}
然后就是轻车熟路的cmake编译过程了。
$ mkdir build
$ cd build
$ cmake ..
$ make
$ ./test_SiftGPU
结果如下图所示
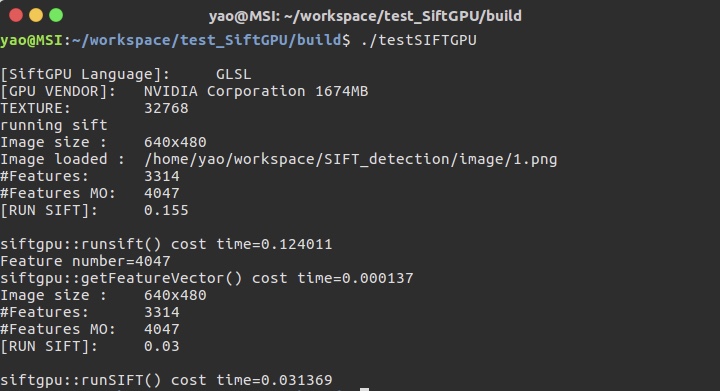
测试代码只调用了OpenGL,我笔记本的配置是i7-7700HQ,显卡GTX1050,可以看到在OpenCV已经读取了图片的情况下,提取出一张图像中所有的SIFT特征点只需要31毫秒,直接读取一张图进行SIFT特征提取的时候,需要100多毫秒,这与传统的SIFT提取消耗的时间相差不多。多数情况下,我们都是调用OpenCV进行图像的读取以及后续的处理,因此使用SiftGPU可以加快提取特征点的速度。在无人机平台上,图像处理速度一般要求在20HZ以上,因此SiftGPU获取特征点的策略可以应用于无人机平台,与ORB等算子速度相当。
CUDA
我们切换至CUDA下进行特征点提取,关于调用CUDA来完成SiftGPU的测试,github上的原作者写的比较含糊,网络上也鲜有教程,因此特做记录如下。
首先切换至SiftGPU的安装路径,找到makefile中的
ifneq ($(simple_find_cuda), )
siftgpu_enable_cuda = 0
else
siftgpu_enable_cuda = 0
endif
CUDA_INSTALL_PATH = /usr/local/cuda
#change additional settings, like SM version here if it is not 1.0 (eg. -arch sm_13 for GTX280)
#siftgpu_cuda_options = -Xopencc -OPT:unroll_size=200000
#siftgpu_cuda_options = -arch sm_10
改为
ifneq ($(simple_find_cuda), )
siftgpu_enable_cuda = 1
else
siftgpu_enable_cuda = 0
endif
CUDA_INSTALL_PATH = /usr/local/cuda
#change additional settings, like SM version here if it is not 1.0 (eg. -arch sm_13 for GTX280)
#siftgpu_cuda_options = -Xopencc -OPT:unroll_size=200000
siftgpu_cuda_options = -arch sm_50
其中最后一行的sm_50取决于读者电脑的GPU算力,笔者笔记本使用的GPU是Pascal架构的GTX1050,算力为5.2,因此采用sm_50这个参数,关于不同GPU的算力可以参考这篇博客。之后重新编译安装SiftGPU。
我们切回到SiftGPU的测试程序,找到主程序main.cpp
char* myargv[4] ={ "-fo", "-1", "-v", "1"};
sift.ParseParam(4, myargv);
改为
char* myargv[5] ={ "-fo", "-1", "-v", "1", "-cuda"};
sift.ParseParam(5, myargv);
然后cmake编译,就可以测试了,测试结果如下
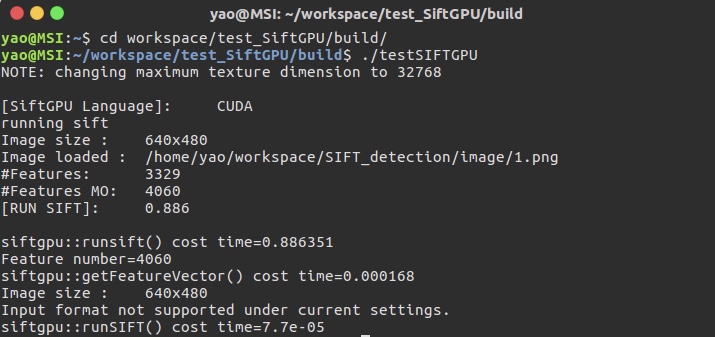
直接读取图片进行SiftGPU的测试运行时间约为88ms,相较于使用OpenGL的测试速度提升了少许,但还没有质的飞跃,当然也