om xxx where a=xxx and b=xxx order by c;
而下列语句则不行,需要执行一次filesort排序操作。
select ... from xxx where a=xxx order by c;
4. 最左前缀原则
对于有很多字段的一张表,查询的方式是多样的,难道要为了每一种可能的查询都定义索引吗?这样岂不是很浪费空间,毕竟建索引也是需要一些空间的。事实上,B+ 树这种索引结构,可以利用索引的“最左前缀”原则来定位记录,避免重复定义索引。
以下面的例子进行说明什么是“最左前缀原则”。
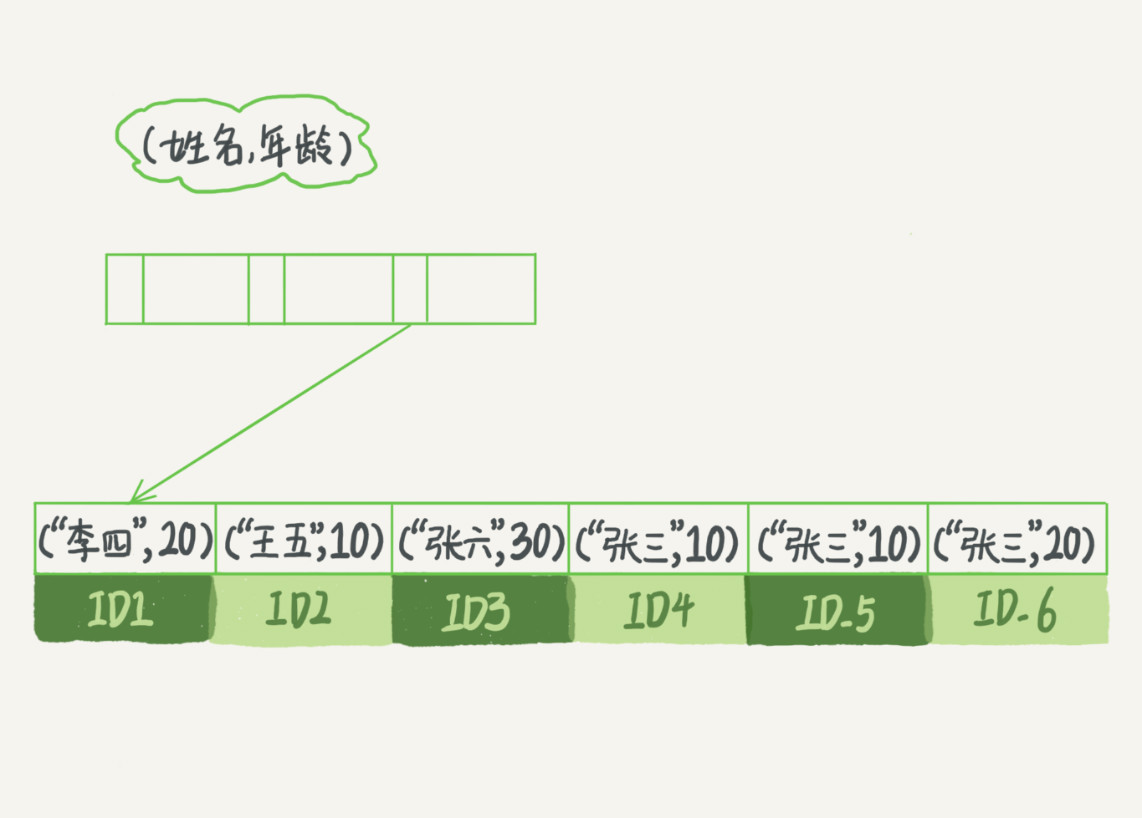
假设建立了一个联合索引(name,age),可以看到,索引项是按照索引定义里面出现的字段顺序排序的,先根据名字排序,名字相同的就根据年龄排序。
当你的逻辑需求是查到所有名字是“张三”的人时,可以快速定位到 ID4,然后向后遍历得到所有需要的结果。
如果你要查的是所有名字第一个字是“张”的人,你的 SQL 语句的条件是"where name like ‘张%’"。这时,你也能够用上这个索引,查找到第一个符合条件的记录是 ID3,然后向后遍历,直到不满足条件为止。
可以看到,不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
因此,基于最左前缀原则,我们在定义联合索引的时候,考虑如何安排索引内的字段顺序就至关重要了!评估的标准就是索引的复用能力,比如,当已经有了(a,b)字段的索引,一般就不需要再单独在a上建立索引了。
5. 覆盖索引
还是利用“2.3 B+树索引”提到过的表,如果执行的语句是:
select * from T where k between 3 and 5;
则这条SQL语句的执行流程如下:
- 在 k 索引树上找到 k=3 的记录,取得 ID = 300;
- 再到 ID 索引树查到 ID=300 对应的 R3;
- 在 k 索引树取下一个值 k=5,取得 ID=500;
- 再回到 ID 索引树查到 ID=500 对应的 R4;
- 在 k 索引树取下一个值k=6,不满足条件,循环结束。
在这个过程中,回到主键索引树的过程,称为回表。在这个例子中,由于查询的结果是所有字段,所需要的数据只有主键上才有,所以不得不回表。但如果执行的语句是下面这样的,注意!这里查询的结果只是“ID”(恰好是主键),而不是所有字段了。
select ID from T where k between 3 and 5;
由于查询的值是ID,而ID的值已经在k索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里,索引k已经“覆盖了”我们的查询需求,故称为覆盖索引。
除了上面这种情况,针对某些统计问题时,覆盖索引也能发挥用处。还是以上面的例子,执行如下语句来统计表的记录总数(在此我们假设这张表数据量特别特别大,需要多次磁盘IO):
select count(*) from T;
如果没有对字段k设置索引,那么只能是通过聚簇索引来计算;如果对字段k设置了索引,那么,由于聚簇索引的叶结点存放的是整行记录的所有信息,而辅助索引的叶结点只存放主键,两者相比,对于一页内存,显然辅助索引能够存放的节点更多,意味着辅助索引可以减少IO次数,从而更快的计算出count(*)的值。
验证如下:
没有对字段k设置索引时,优化器会选择聚簇索引进行操作(即key为PRIMARY)。

对字段k设置了索引时,优化器会选择辅助索引进行操作(即key为k)

可见,如果建立了辅助索引,在有些场景下,优化器会自动使用辅助索引从而提升查询效率。
总结:覆盖索引就是从辅助索引中就能直接得到查询结果,而不需要回表到聚簇索引中进行再次查询,所以可以减少搜索次数(不需要从辅助索引树回表到聚簇索引树),或者说减少IO操作(通过辅助索引树可以一次性从磁盘载入更多节点),从而提升性能。
6. 索引下推
什么是索引下推(Index Condition Pushdown,ICP)呢?假设有这么个需求,查询表中“名字第一个字是张,性别男,年龄为10岁的所有记录”。那么,查询语句是这么写的:
mysq> select * from tuser where name like '张 %' and age=10 and ismale=1;
根据前面说的“最左前缀原则”,该语句在搜索索引树的时候,只能匹配到名字第一个字是‘张’的记录(即记录ID3),接下来是怎么处理的呢?当然就是从ID3开始,逐个回表,到主键索引上找出相应的记录,再比对age和ismale这两个字段的值是否符合。
但是!MySQL 5.6引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表字数。
下面图1、图2分别展示这两种情况。
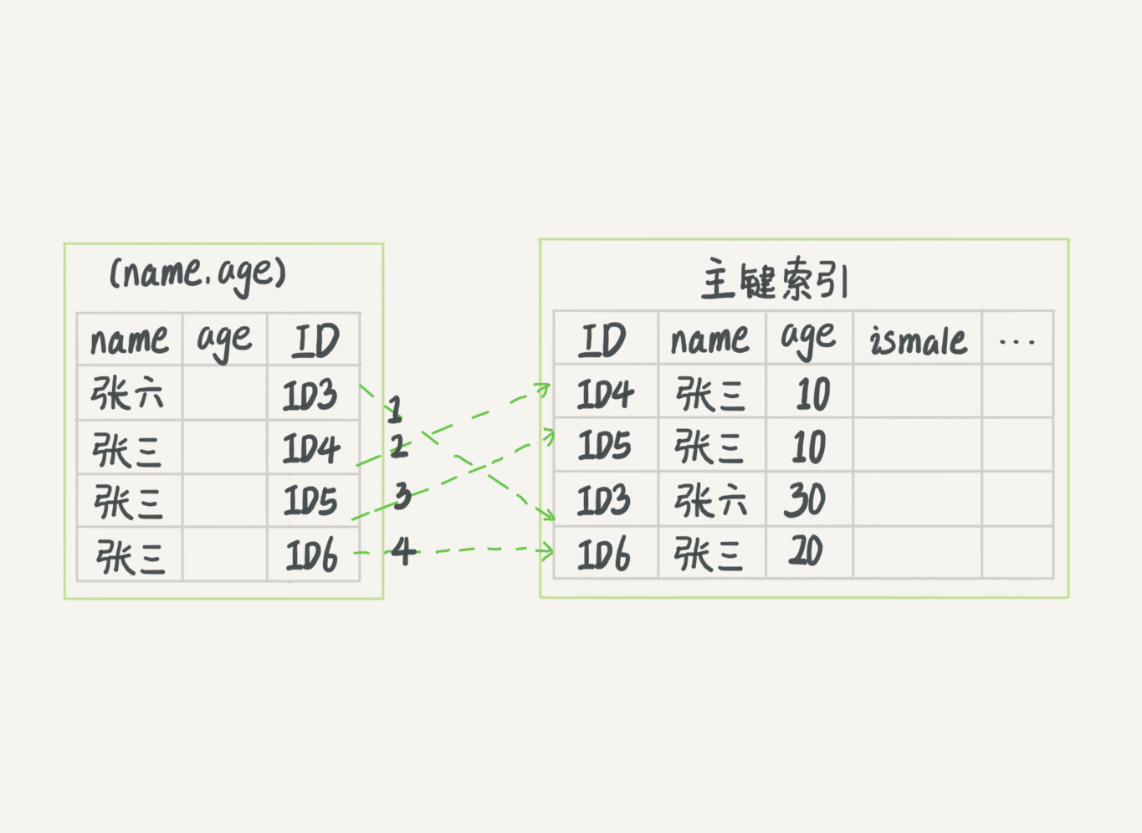
(图1)
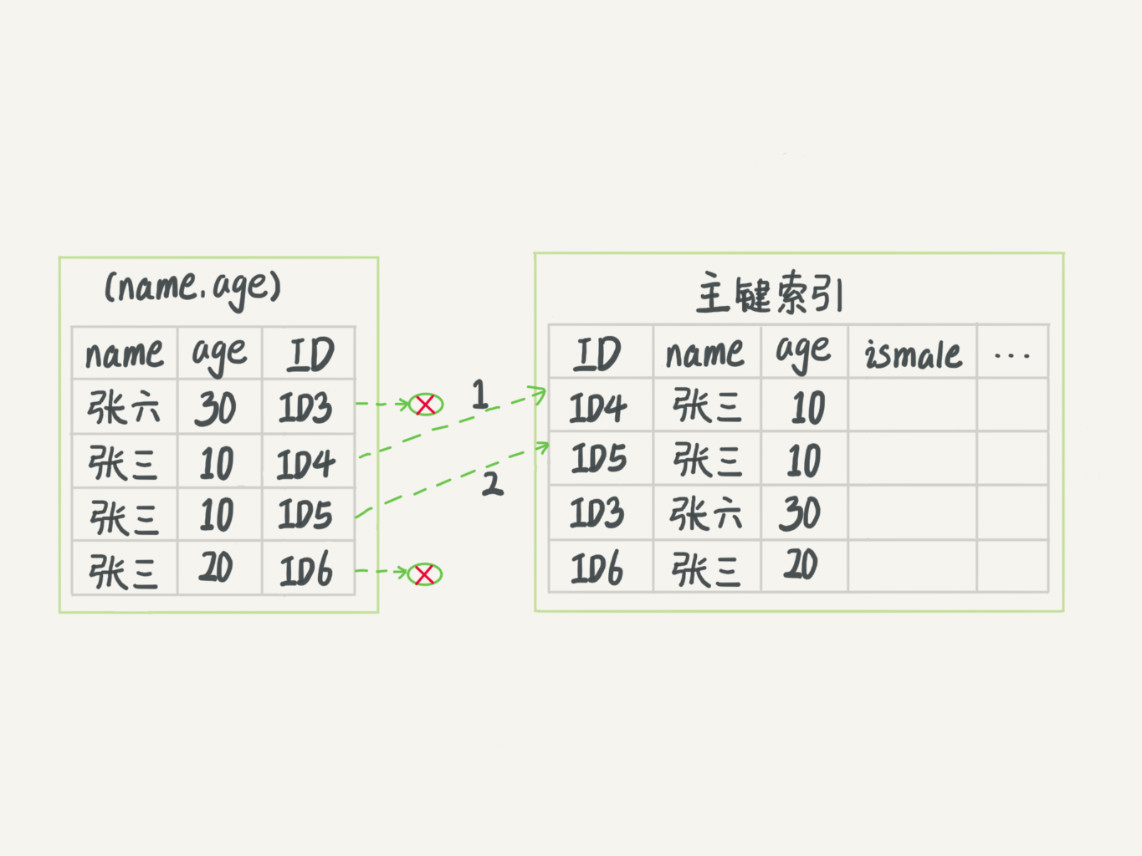
(图2)
图 1 中,在 (name,age) 索引里面我特意去掉了 age 的值,这个过程 InnoDB 并不会去看 age 的值,只是按顺序把“name 第一个字是’张’”的记录一条条取出来回表。因此,需要回表 4 次。
图 2 跟图 1 的区别是,InnoDB 在 (name,age) 索引内部就判断了 age 是否等于 10,对于不等于 10 的记录,直接判断并跳过。在我们的这个例子中,只需要对 ID4、ID5 这两条记录回表取数据判断,就只需要回表 2 次。
总结:如果没有索引下推优化(或称ICP优化),当进行索引查询时,首先根据索引来查找记录,然后再根据where条件来过滤记录;在支持ICP优化后,MySQL会在取出索引的同时,判断是否可以进行where条件过滤,也就是说提前执行where的部分过滤操作,在某些场景下,可以大大减少回表次数,从而提升整体性能。
总结:
学习完本节内容,需要问问自己:
(1)索引的常见数据结构有哪些?(哈希表,有序数组,B+树),它们分别有怎样的特点?分别适合哪些应用场景?
(2)主键索引(也称聚簇索引)和非主键索引(也称辅助索引/二级索引)的概念是什么?回表的概念又是什么?
(3)什么是联合索引,什么是最左前缀原则?(由于MySQL的最左前缀特性,建立联合索引的时候对字段的顺序应该要多考虑)。什么是覆盖索引?能否清楚的说出Index Condition Pushdown优化的原理?
---
参考:
- 《高性能MySQL》
- 《MySQL技术内幕-InnoDB存储引擎》
- 极客时间“MySQL实战45讲”专栏第4、5讲