部分数据分区。
在进行分区之前可以用如下方法 看下数据库表是否支持分区哈
mysql> show variables like '%partition%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| have_partitioning | YES |
+-------------------+-------+
1 row in set (0.00 sec)
方案二:数据库分表
为什么要分表:分表后,显而易见,单表数据量降低,树的高度变低,查询经历的磁盘io变少,则可以提高效率
mysql 分表分为两种 水平分表和垂直分表
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
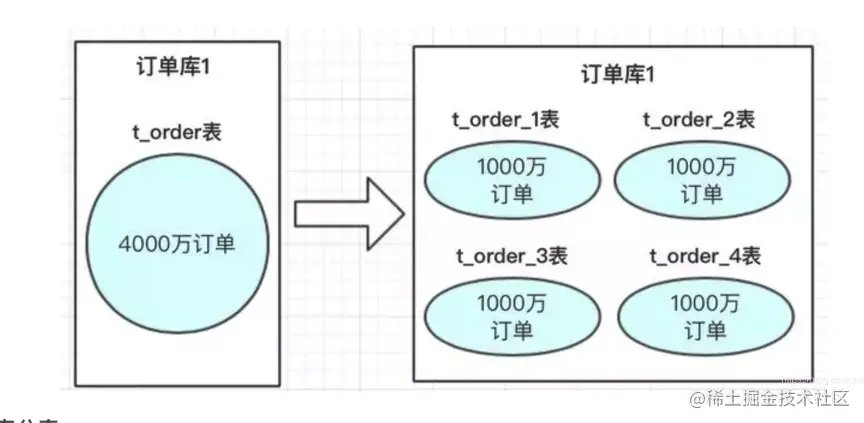
水平分表
定义:数据表行的拆分,通俗点就是把数据按照某些规则拆分成多张表或者多个库来存放。分为库内分表和分库。 比如一个表有4000万数据,查询很慢,可以分到四个表,每个表有1000万数据
垂直分表
定义:列的拆分,根据表之间的相关性进行拆分。常见的就是一个表把不常用的字段和常用的字段就行拆分,然后利用主键关联。或者一个数据库里面有订单表和用户表,数据量都很大,进行垂直拆分,用户库存用户表的数据,订单库存订单表的数据

缺点:垂直分隔的缺点比较明显,数据不在一张表中,会增加join 或 union之类的操作
知道了两个知识后,我们来看一下分库分表的方案
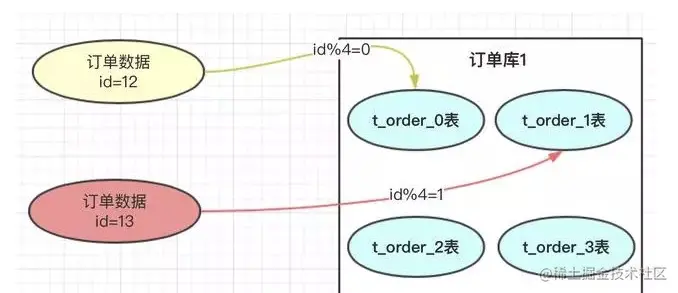
1.取模方案:
拆分之前,先预估一下数据量。比如用户表有4000w数据,现在要把这些数据分到4个表user1 user2 uesr3 user4。 比如id = 17,17对4取模为1,加上 ,所以这条数据存到user2表。
注意:进行水平拆分后的表要去掉auto_increment自增长。这时候的id可以用一个id 自增长临时表获得,或者使用 redis incr的方法。
优点: 数据均匀的分到各个表中,出现热点问题的概率很低。
缺点:以后的数据扩容迁移比较困难难,当数据量变大之后,以前分到4个表现在要分到8个表,取模的值就变了,需要重新进行数据迁移。
2.range 范围方案
以范围进行拆分数据,就是在某个范围内的订单,存放到某个表中。比如id=12存放到user1表,id=1300万的存放到user2 表。

优点:有利于将来对数据的扩容
缺点:如果热点数据都存在一个表中,则压力都在一个表中,其他表没有压力。
我们看到以上两种方案 都存在缺点 但是却又是互补的,那么我们将这两个方案结合会怎样呢?
3.hash取模和range方案结合
如下图 我们可以看到 group 组存放id 为0~4000万的数据,然后有三个数据库 DB0 DB1 DB2,DB0里面有四个数据库,DB1 和DB2 有三个数据库
假如id为15000 然后对10取模(为啥对10 取模 因为有10个表),取0 然后 落在DB_0,然后在根据range 范围,落在Table_0 里面。

总结:采用hash取模和range方案结合 既可以避免热点数据的问题,也有利于将来对数据的扩容
我们已经了解了 mysql分区和分表的知识 那我们看一下这两个技术有何不同以及适用场景
分区分表的区别:
1、实现方式上
- mysql的分表是真正的分表,一张表分成很多表后,每一个小表都是完整的一张表,都对应三个文件,一个.MYD数据文件,.MYI索引文件,.frm表结构
- 分区不一样,一张大表进行分区后,他还是一张表,不会变成二张表,但是他存放数据的区块变多了。
2、提高性能上
- 分表重点是存取数据时,如何提高mysql并发能力上;
- 而分区呢,如何突破磁盘的读写能力,从而达到提高mysql性能的目的。
3、实现的难易度上
1、分表的方法有很多,用merge来分表,是最简单的一种方式。这种方式根分区难易度差不多,并且对程序代码来说可以做到透明的。如果是用其他分表方式就比分区麻烦了。 2、分区实现是比较简单的,建立分区表,根建平常的表没什么区别,并且对开代码端来说是透明的
分区分表的联系
1、都能提高mysql的性高,在高并发状态下都有一个良好的表现。
2、分表和分区不矛盾,可以相互配合的,对于那些大访问量,并且表数据比较多的表,我们可以采取分表和分区结合的方式,访问量不大,但是表数据很多的表,我们可以采取分区的方式等。
分库分表存在的问题
1、事务问题
在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
2、跨库跨表的join问题
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
3、额外的数据管理负担和数据运算压力
额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算,例如,对于一个记录用户成绩的用户数据表userTable,业务要求查出成绩最好的100位,在进行分表之前,只需一个order by语句就可以搞定,但是在进行分表之后,将需要n个order by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并计算,才能得出结果。
方案三:冷热归档
为什么要冷热归档:其实原因和方案二类似,都是降低单表数据量,树的高度变低,查询经历的磁盘io变少,则可以提高效率 如果大家的业务数据,有明显的冷热区分,比如:只需要展示近一周或一个月的数据。那么这种情况这一周喝一个月的数据我们称之为热数据,其余数据为冷数据。那么我们可以将冷数据归档在其他的库表中,提高我们热数据的操作效率。
接下来讲一下归档的过程
- 创建归档表 创建的归档表 原则上要与原表保持一致
- 归档表数据的初始化

- 业务增量数据处理过程

- 数据的获取过程
以上三种方案我们如何选型
| 方案 |
试用场景 |
优点 |
缺点 |
| 数据表分区 |
1.数据量较大 2.查询场景只在某个区 3.没有联合查询的场景 |
分区分表是在物理上对数据表所对应的文件进行拆分,对应的表名是不变的,所以不会影响到之前业务逻辑的sql |
分表后的查询等业务会创建对应的对象,也会造成一定的开销分区数据若要聚合的话 耗费时间也较长;使用范围不适合数据量千万级以上的 |
| 数据表分表 |
数据量较大,无法区分明显冷热区 且数据可以完整按照区间划分 |
适用于对冷热分区的界限不是很明显的数据,对后续类似的数据可以采用该方式,将大表拆分成小表 提高查询插入等效率 |
若大数据表逐渐增多 那么对应的数据库表越来越多 每个表都需要分表;区间的划分较为固定 若后续单表的数据量大起来 也会对性能造成影响;实现复杂度相对方案三比较复杂 需要测试整个实现过程 在编码层处理 对原有业务有影响; |
| 冷热归档分库 |
数据量较大;数据冷热分 |