限有关。
2、Hyperloglog。HyperLogLog 是用来做基数统计的算法,其优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。典型的使用场景是统计独立访客。
3、Geospatial :主要用于存储地理位置信息,并对存储的信息进行操作,适用场景如定位、附近的人等。
SortedSet和List异同点?
相同点:
- 都是有序的;
- 都可以获得某个范围内的元素。
不同点:
- 列表基于链表实现,获取两端元素速度快,访问中间元素速度慢;
- 有序集合基于散列表和跳跃表实现,访问中间元素时间复杂度是OlogN;
- 列表不能简单的调整某个元素的位置,有序列表可以(更改元素的分数);
- 有序集合更耗内存。
Redis的内存用完了会怎样?
如果达到设置的上限,Redis的写命令会返回错误信息(但是读命令还可以正常返回)。
也可以配置内存淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
Redis如何做内存优化?
可以好好利用Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的Key-Value可以用更紧凑的方式存放到一起。尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面。
keys命令存在的问题?
redis的单线程的。keys指令会导致线程阻塞一段时间,直到执行完毕,服务才能恢复。scan采用渐进式遍历的方式来解决keys命令可能带来的阻塞问题,每次scan命令的时间复杂度是O(1),但是要真正实现keys的功能,需要执行多次scan。
scan的缺点:在scan的过程中如果有键的变化(增加、删除、修改),遍历过程可能会有以下问题:新增的键可能没有遍历到,遍历出了重复的键等情况,也就是说scan并不能保证完整的遍历出来所有的键。
Redis事务
事务的原理是将一个事务范围内的若干命令发送给Redis,然后再让Redis依次执行这些命令。
事务的生命周期:
-
使用MULTI开启一个事务
-
在开启事务的时候,每次操作的命令将会被插入到一个队列中,同时这个命令并不会被真的执行
-
EXEC命令进行提交事务
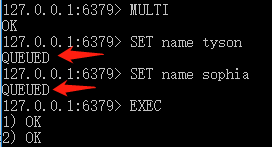
一个事务范围内某个命令出错不会影响其他命令的执行,不保证原子性:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set a 1
QUEUED
127.0.0.1:6379> set b 1 2
QUEUED
127.0.0.1:6379> set c 3
QUEUED
127.0.0.1:6379> exec
1) OK
2) (error) ERR syntax error
3) OK
WATCH命令
WATCH命令可以监控一个或多个键,一旦其中有一个键被修改,之后的事务就不会执行(类似于乐观锁)。执行EXEC命令之后,就会自动取消监控。
127.0.0.1:6379> watch name
OK
127.0.0.1:6379> set name 1
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set name 2
QUEUED
127.0.0.1:6379> set gender 1
QUEUED
127.0.0.1:6379> exec
(nil)
127.0.0.1:6379> get gender
(nil)
比如上面的代码中:
watch name开启了对name这个key的监控- 修改
name的值
- 开启事务a
- 在事务a中设置了
name和gender的值
- 使用
EXEC命令进提交事务
- 使用命令
get gender发现不存在,即事务a没有执行
使用UNWATCH可以取消WATCH命令对key的监控,所有监控锁将会被取消。
Redis事务支持隔离性吗?
Redis 是单进程程序,并且它保证在执行事务时,不会对事务进行中断,事务可以运行直到执行完所有事务队列中的命令为止。因此,Redis 的事务是总是带有隔离性的。
Redis事务保证原子性吗,支持回滚吗?
Redis单条命令是原子性执行的,但事务不保证原子性,且没有回滚。事务中任意命令执行失败,其余的命令仍会被执行。
持久化机制
持久化就是把内存的数据写到磁盘中,防止服务宕机导致内存数据丢失。
Redis支持两种方式的持久化,一种是RDB的方式,一种是AOF的方式。前者会根据指定的规则定时将内存中的数据存储在硬盘上,而后者在每次执行完命令后将命令记录下来。一般将两者结合使用。
RDB方式
RDB是 Redis 默认的持久化方案。RDB持久化时会将内存中的数据写入到磁盘中,在指定目录下生成一个dump.rdb文件。Redis 重启会加载dump.rdb文件恢复数据。
bgsave是主流的触发 RDB 持久化的方式,执行过程如下:
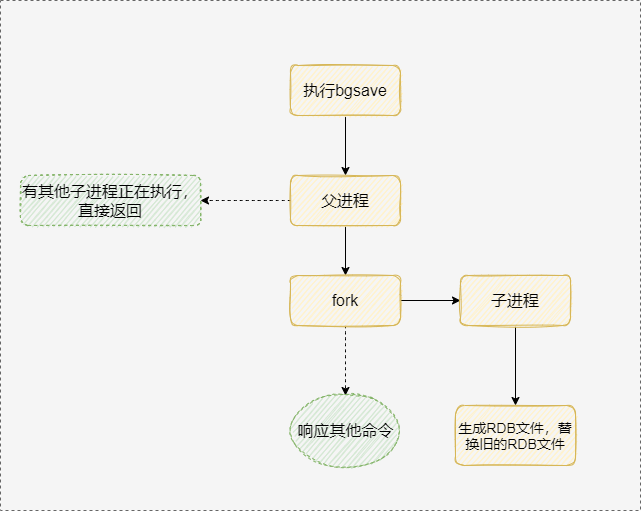
- 执行
BGSAVE命令
- Redis 父进程判断当前是否存在正在执行的子进程,如果存在,
BGSAVE命令直接返回。
- 父进程执行
fork操作创建子进程,fork操作过程中父进程会阻塞。
- 父进程
fork完成后,父进程继续接收并处理客户端的请求,而子进程开始将内存中的数据写进硬盘的临时文件;
- 当子进程写完所有数据后会用该临时文件替换旧的 RDB 文件。
Redis启动时会读取RDB快照文件,将数据从硬盘载入内存。通过 RDB 方式的持久化,一旦Redis异常退出,就会丢失最近一次持久化以后更改的数据。
触发 RDB 持久化的方式:
-
手动触发:用户执行SAVE或BGSAVE命令。SAVE命令执行快照的过程会阻塞所有客户端的请求,应避免在生产环境使用此命令。BGSAVE命令可以在后台异步进行快照操作,快照的同时服务器还可以继续响应客户端的请求,因此需要手动执行快照时推荐使用BGSAVE命令。
-
被动触发:
- 根据配置规则进行自动快照,如
SAVE 100 10,100秒内至少有10个键被修改则进行快照。
- 如果从节点执行全量复制操作,主节点会自动执行
BGSAVE生成 RDB 文件并发送给从节点。
- 默认情况下执行
shutdown命令时,如果没有开启 AOF 持久化功能则自动执行·BGSAVE·。
优点:
- Redis 加载 RDB 恢复数据远远快于 AOF 的方式。
- 使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 Redis 的高性能。
缺点:
- RDB方式数据无法做到实时持久化。因为
BGSAVE每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本比较高。
- RDB 文件使用特定二进制格式保存,Redis 版本升级过程中有多个格式的 RDB 版本,存在老版本 Redis 无法兼容新版 RDB 格式的问题。
AOF方式
AOF(append only file)持久化:以独立日志的方式记录每次写命令,Redis重启时会重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,AOF 是Redis持久化的主流方式。
默认情况下Red