is没有开启AOF方式的持久化,可以通过appendonly参数启用:appendonly yes。开启AOF方式持久化后每执行一条写命令,Redis就会将该命令写进aof_buf缓冲区,AOF缓冲区根据对应的策略向硬盘做同步操作。
默认情况下系统每30秒会执行一次同步操作。为了防止缓冲区数据丢失,可以在Redis写入AOF文件后主动要求系统将缓冲区数据同步到硬盘上。可以通过appendfsync参数设置同步的时机。
appendfsync always //每次写入aof文件都会执行同步,最安全最慢,不建议配置
appendfsync everysec //既保证性能也保证安全,建议配置
appendfsync no //由操作系统决定何时进行同步操作
接下来看一下 AOF 持久化执行流程:
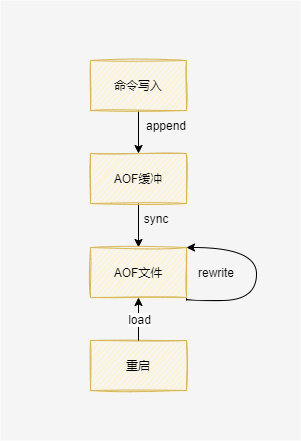
- 所有的写入命令会追加到 AOP 缓冲区中。
- AOF 缓冲区根据对应的策略向硬盘同步。
- 随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩文件体积的目的。AOF文件重写是把Redis进程内的数据转化为写命令同步到新AOF文件的过程。
- 当 Redis 服务器重启时,可以加载 AOF 文件进行数据恢复。
优点:
- AOF可以更好的保护数据不丢失,可以配置 AOF 每秒执行一次
fsync操作,如果Redis进程挂掉,最多丢失1秒的数据。
- AOF以
append-only的模式写入,所以没有磁盘寻址的开销,写入性能非常高。
缺点:
- 对于同一份文件AOF文件比RDB数据快照要大。
- 数据恢复比较慢。
RDB和AOF如何选择?
通常来说,应该同时使用两种持久化方案,以保证数据安全。
- 如果数据不敏感,且可以从其他地方重新生成,可以关闭持久化。
- 如果数据比较重要,且能够承受几分钟的数据丢失,比如缓存等,只需要使用RDB即可。
- 如果是用做内存数据,要使用Redis的持久化,建议是RDB和AOF都开启。
- 如果只用AOF,优先使用everysec的配置选择,因为它在可靠性和性能之间取了一个平衡。
当RDB与AOF两种方式都开启时,Redis会优先使用AOF恢复数据,因为AOF保存的文件比RDB文件更完整。
Redis有哪些部署方案?
单机版:单机部署,单机redis能够承载的 QPS 大概就在上万到几万不等。这种部署方式很少使用。存在的问题:1、内存容量有限 2、处理能力有限 3、无法高可用。
主从模式:一主多从,主负责写,并且将数据复制到其它的 slave 节点,从节点负责读。所有的读请求全部走从节点。这样也可以很轻松实现水平扩容,支撑读高并发。master 节点挂掉后,需要手动指定新的 master,可用性不高,基本不用。
哨兵模式:主从复制存在不能自动故障转移、达不到高可用的问题。哨兵模式解决了这些问题。通过哨兵机制可以自动切换主从节点。master 节点挂掉后,哨兵进程会主动选举新的 master,可用性高,但是每个节点存储的数据是一样的,浪费内存空间。数据量不是很多,集群规模不是很大,需要自动容错容灾的时候使用。
Redis cluster:服务端分片技术,3.0版本开始正式提供。Redis Cluster并没有使用一致性hash,而是采用slot(槽)的概念,一共分成16384个槽。将请求发送到任意节点,接收到请求的节点会将查询请求发送到正确的节点上执行。主要是针对海量数据+高并发+高可用的场景,如果是海量数据,如果你的数据量很大,那么建议就用Redis cluster,所有主节点的容量总和就是Redis cluster可缓存的数据容量。
主从架构
单机的 redis,能够承载的 QPS 大概就在上万到几万不等。对于缓存来说,一般都是用来支撑读高并发的。因此架构做成主从(master-slave)架构,一主多从,主负责写,并且将数据复制到其它的 slave 节点,从节点负责读。所有的读请求全部走从节点。这样也可以很轻松实现水平扩容,支撑读高并发。
Redis的复制功能是支持多个数据库之间的数据同步。主数据库可以进行读写操作,当主数据库的数据发生变化时会自动将数据同步到从数据库。从数据库一般是只读的,它会接收主数据库同步过来的数据。一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库。
主从复制的原理?
- 当启动一个从节点时,它会发送一个
PSYNC 命令给主节点;
- 如果是从节点初次连接到主节点,那么会触发一次全量复制。此时主节点会启动一个后台线程,开始生成一份
RDB 快照文件;
- 同时还会将从客户端 client 新收到的所有写命令缓存在内存中。
RDB 文件生成完毕后, 主节点会将RDB文件发送给从节点,从节点会先将RDB文件写入本地磁盘,然后再从本地磁盘加载到内存中;
- 接着主节点会将内存中缓存的写命令发送到从节点,从节点同步这些数据;
- 如果从节点跟主节点之间网络出现故障,连接断开了,会自动重连,连接之后主节点仅会将部分缺失的数据同步给从节点。
哨兵Sentinel
主从复制存在不能自动故障转移、达不到高可用的问题。哨兵模式解决了这些问题。通过哨兵机制可以自动切换主从节点。
客户端连接Redis的时候,先连接哨兵,哨兵会告诉客户端Redis主节点的地址,然后客户端连接上Redis并进行后续的操作。当主节点宕机的时候,哨兵监测到主节点宕机,会重新推选出某个表现良好的从节点成为新的主节点,然后通过发布订阅模式通知其他的从服务器,让它们切换主机。
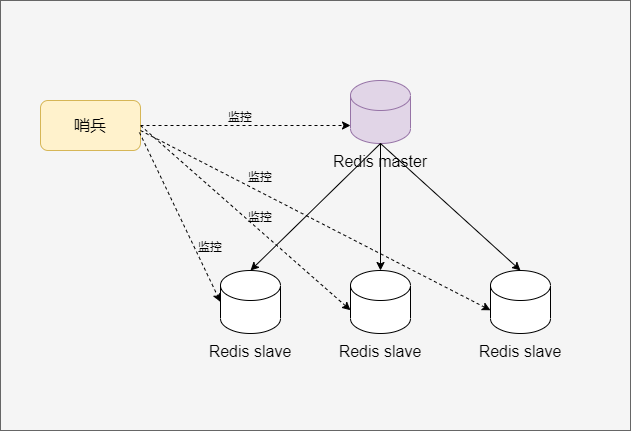
工作原理
- 每个
Sentinel以每秒钟一次的频率向它所知道的Master,Slave以及其他 Sentinel 实例发送一个 PING命令。
- 如果一个实例距离最后一次有效回复
PING 命令的时间超过指定值, 则这个实例会被 Sentine 标记为主观下线。
- 如果一个
Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master是否真正进入主观下线状态。
- 当有足够数量的
Sentinel(大于等于配置文件指定值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 。若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被解除。 若 Master重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
- 哨兵节点会选举出哨兵 leader,负责故障转移的工作。
- 哨兵 leader 会推选出某个表现良好的从节点成为新的主节点,然后通知其他从节点更新主节点信息。
Redis cluster
哨兵模式解决了主从复制不能自动故障转移、达不到高可用的问题,但还是存在主节点的写能力、容量受限于单机配置的问题。而cluster模式实现了Redis的分布式存储,每个节点存储不同的内容,解决主节点的写能力、容量受限于单机配置的问题。
Redis cluster集群节点最小配置6个节点以上(3主3从),其中主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用。
Redis cluster采用虚拟槽分区,所有的键根据哈希函数映射到0~16383个整数槽内,每个节点负责维护一部分槽以及槽所映射的键值数据。
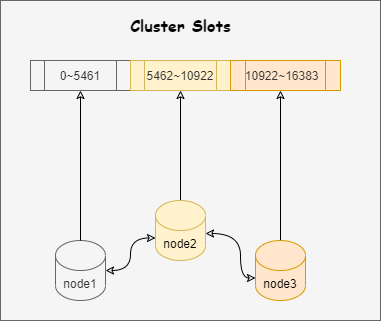
工作原理:
- 通过哈希的方式,将数据分片,每个节点均分存储一定哈希槽(哈希值)区间的数据,默认分配了