±ľĆŞÖ÷ŇŞ˝éÉÜJava NIOµÄ»ů±ľÔŔíşÍÖ÷ŇŞ×éĽţ
NettyĘÇÓÉJBOSSĚáą©µÄJavażŞÔ´ÍřÂçÓ¦ÓĂłĚĐňżňĽÜŁ¬Ćäµ×˛ăĘÇ»ůÓÚJavaĚáą©µÄNIOÄÜÁ¦ĘµĎֵġŁŇň´ËÎŞÁËŐĆÎŐNettyµÄµ×˛ăÔŔíŁ¬ĐčŇŞĘ×ĎČÁË˝âJava NIOµÄÔŔíˇŁ
NIOĽň˝é
ĽĆËă»úÖ÷ŇŞÓÉCPUˇ˘Äڴ桢Íâ´ćˇ˘IOÉ豸µČÓ˛Ľţ×éłÉŁ¬ĽĆËă»úÖ´ĐĐĽĆËăµÄąýłĚľÍĘÇCPU´ÓÄÚ´ćÖĐ»ńȡĘýľÝŁ¬˝řĐĐĽĆË㣬ȻşóÔŮ˝«ĽĆËă˝áąűĐ´ČëÄÚ´ćÖСŁµ«ÓÉÓÚÄÚ´ć·ÇłŁ°şąóÇŇϵçşóĘýľÝ»á¶ŞĘ§Ł¬ĽĆËă»úĐčŇŞĘąÓĂÍâ´ćŔ´łÖľĂ»Ż´ć´˘´óąćÄŁµÄĘýľÝŁ¬Íâ´ćĚáą©ÁË´óÁżµÄ´ć´˘żŐĽäŁ¬´úĽŰĘÇĆä´ćȡËٶČԶСÓÚÄڴ档łýÁ˶ÁȡÍâ´ćĘýľÝŁ¬ĽĆËă»ú»ążÉŇÔ´ÓÍřÂçÉ豸»ńȡÍřÂçÖеÄĘýľÝŁ¬ĘÜÍřÂç´«ĘäËٶȵÄĎŢÖĆŁ¬ĽĆËă»ú»ńȡÍřÂçĘýľÝµÄËٶČҲԶСÓÚĆä¶ÁȡÄÚ´ćµÄËٶȡŁ
¶ÔÓÚ´ćȡŐâĐ©µÍËŮIOÉ豸Ł¬˛Ů×÷ϵͳŁ¨ČçLinuxŁ©Ěáą©ÁË5ÖÖ˛»Í¬µÄIOÄŁĐ͡Ł¶ÔÓÚJavaŔ´ËµŁ¬Ćä×îĎČĚáą©µÄľÍĘÇ»ůÓÚ×îĽňµĄµÄ×čČűĘ˝IOÄŁĐÍʵĎÖµÄBIO(Blocking IO)żâˇŁµ±µ÷ÓĂBIOżâ¶ÁȡӲĹĚÖеÄĘýľÝʱŁ¬ÓĂ»§˝řłĚ»áһֱ±»×čČűÔÚ¶ÁĘýľÝµÄ˝ÓżÚÉĎŁ¬Ö±µ˝ĘýľÝ±»˛Ů×÷ϵͳ´ÓÓ˛ĹĚÖĐ»ńȡłöŔ´˛˘·µ»Ř¸řÓĂ»§Ł¬ŐâʱÓĂ»§˝řłĚ˛ĹÄÜĽĚĐřĎňĎÂÖ´ĐСŁÓÉÓÚ¶ÁȡӲĹĚËٶČĎŕ±ČCPUĽĆËăËٶČÂýşÜ¶ŕŁ¬˝řłĚľÍ»áһֱ±»ż¨ÔÚ¶ÁȡĘýľÝŐâŔÓĂ»§ĚĺŃéľÍĘÇ˝řłĚĂ»ÓĐĎěÓ¦ˇŁĽ´ĘąCPU´¦ÓÚżŐĎĐ״̬Ł¬Ň˛ÎŢ·¨ĘąÓĂCPU˝řĐĐĆäËűą¤×÷ˇŁŐâľÍŔË·ŃÁË´óÁżµÄ×ĘÔ´Ł¬Í¬Ę±Ň˛¸řÓĂ»§ÔěłÉÁ˲»şĂµÄĚĺŃ顣
łýÁË×î´«ÍłµÄ×čČűĘ˝IOŁ¬˛Ů×÷ϵͳ»ąĚáą©ÁËĆäËűĽ¸ÖָĽřµÄIOÄŁĐÍŁ¬×ÜĚĺËĽĎ붼ĘÇľˇżÉÄÜĽőÉŮÓĂ»§˝řłĚ×čČűÔÚIOÉϵÄʱĽäŁ¬ÔÚ˝řĐĐÂýËŮÉ豸IOʱŁ¬˝řłĚÎŢĐčµČ´ýŁ¬żÉŇÔĽĚĐř´¦ŔíĆäËűÖ¸Áµ±ĘýľÝ»ńȡÍęłÉʱ˛Ů×÷ϵͳÔŮ֪ͨÓĂ»§˝řłĚżÉŇÔ˝řĐĐşóĐřµÄĘýľÝ´¦Ŕí˛Ů×÷ˇŁŇň´ËJavaÔÚ1.4°ć±ľşóľÍÍĆłöÁËŇ»Ě×еÄIO˝ÓżÚNIO(New IO)Ł¬ŐâĚ×IO˝ÓżÚ»ůÓڶ෸´ÓĂIOÄŁĐÍŁ¬Ěáą©ÁË·Ç×čČűµÄIOÄÜÁ¦Ł¬Ňň´ËNIOÖеÄNҲżÉŇÔŔí˝âÎŞNon-blockingˇŁŐâĚ×NIO˝ÓżÚʵĎÖÁËÖ»ÓĂŇ»¸öĎßłĚŔ´ÂÖŃŻµČ´ýËůÓĐÓ¦ÓĂ˝řłĚµÄIOľÍĐ÷״̬Ł¬µ±Äł¸öÓ¦ÓĂ˝řłĚµÄIO״̬ľÍĐ÷ʱŁ¬ÔŮ֪ͨ¶ÔÓ¦˝řłĚ˝řĐĐĘýľÝ¶ÁĐ´µÄ˛Ů×÷ˇŁŐâľÍ±ÜĂâÁËĂż¸öÓ¦ÓĂ˝řłĚÔÚIOʱ±»×čČűŁ¬ÎŞżŞ·˘¸ßĐÔÄܺ͸߲˘·˘µÄÓ¦ÓĂĚáą©Á˹ؼüÄÜÁ¦ˇŁ
NIOµÄ3¸öşËĐÄ×éĽţ
- Channel
- Buffer
- Selector
ChannelŁ¨Í¨µŔŁ©
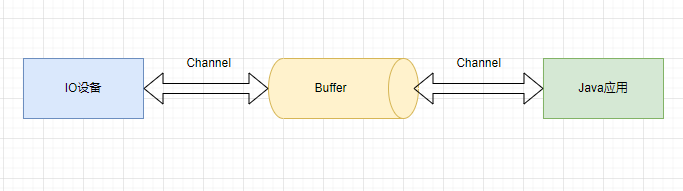
Channel ĘÇ NIO µÄşËĐĸĹÄËü±íʾһ¸ö´ňżŞµÄÁ¬˝ÓŁ¬ĘÇĘýľÝ¶ÁĐ´µÄË«ĎňͨµŔŁ¬Őâ¸öÁ¬˝ÓżÉŇÔÁ¬˝Óµ˝ I/O É豸Ł¨ŔýČ磺´ĹĹĚÎÄĽţŁ¬SocketŁ©»ňŐßŇ»¸öÖ§łÖ I/O ·ĂÎʵÄÓ¦ÓĂłĚĐňŁ¬Java NIO ĘąÓĂ»şłĺÇřşÍͨµŔŔ´˝řĐĐĘýľÝ´«Ę䡣
ChannelµÄÖ÷ҪʵĎÖŔŕÓĐŁş
- FileChannelŁ¨¶ÁĐ´ÎÄĽţŁ©
- DatagramChannelŁ¨UDP±ŕłĚŁ©
- SocketChannelŁ¨TCP±ŕłĚŁ©
- ServerSocketChannelŁ¨TCP±ŕłĚŁ©
FileChannel
FileChannelÖ»ÄÜą¤×÷ÔÚ×čČűÄŁĘ˝ĎÂŁ¬˛»ÄÜĹäşĎSelector
FileChannel˛»ÄÜÖ±˝Ó´ňżŞŁ¬±ŘĐëͨąýFileInputStreamŁ¬FileOutputStream»ňRandomAccessFileŔ´»ńȡŁ¬ËüĂǶĽÓĐgetChannel()·˝·¨
- ͨąý
FileInputStream»ńȡµÄchannelÖ»ÄܶÁ - ͨąý
FileOutputStream»ńȡµÄchannelÖ»ÄÜĐ´ - ͨąý
RandomAccessFileĘÇ·ńÄܶÁĐ´¸ůľÝąąÔěʱµÄ¶ÁĐ´ÄŁĘ˝ľö¶¨
transferTo·˝·¨
ЧÂĘĎŕ±ČĘąÓĂÁ÷Ę˝·˝Ę˝ż˝±´ĘýľÝ¸ßşÜ¶ŕŁ¬µ×˛ăĘąÓĂÁ˲Ů×÷ϵͳĚáą©µÄÁăż˝±´ĚŘĐÔˇŁ
Ň»´Î×î¶ŕ´«Ęä2gµÄĘýľÝ
BufferŁ¨»şłĺÇřŁ©
BufferĘÇNIOµÄÁíŇ»¸öşËĐĸĹÄNIOżâ˛Ů×÷ĘýľÝ¶ĽĘÇͨąý»şłĺÇř´¦ŔíµÄŁ¬ÔÚĘýľÝ¶ÁĐ´µÄąýłĚ¶ĽŇŞĎČľąý»şłĺÇřŁ¬Č»şóÔŮ´Ó»şłĺÇřÖĐ°´ŐŐżéŔ´´¦ŔíĘýľÝˇŁ
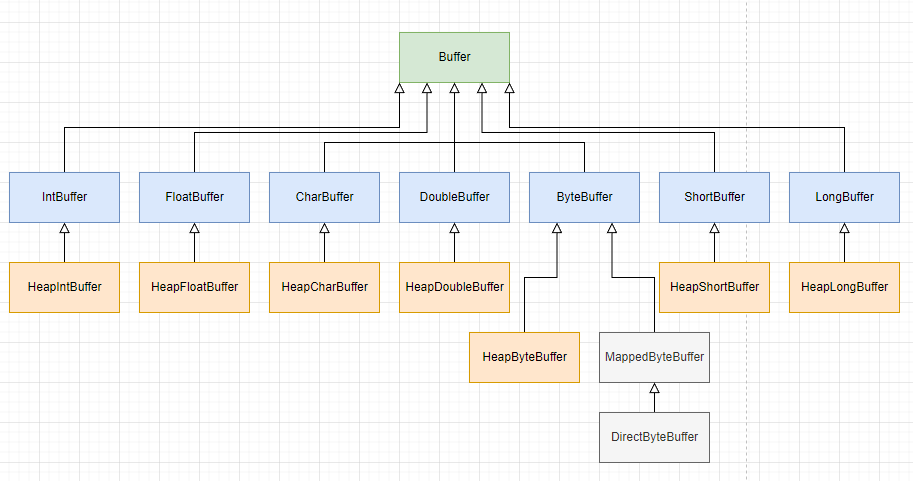
´ÓŔŕÍĽÖĐżÉŇÔż´µ˝Ł¬7 ÖÖĘýľÝŔŕĐͶÔÓ¦×Ĺ 7 ÖÖ×ÓŔ࣬ŐâĐ©Ăű×ÖĘÇ Heap żŞÍ·×ÓŔ࣬ĘýľÝĘÇ´ć·ĹÔÚ JVM ¶ŃÖеġŁ
MappedByteBuffer
MappedByteBuffer´ć·ĹÔÚ¶ŃÍâÖ±˝ÓÄÚ´ćÖĐŁ¬żÉŇÔÓëÎÄĽţ˝řĐĐÓłÉ䡣
ͨąýjava.nio°üşÍMappedByteBufferÔĘĐíJavałĚĐňÖ±˝Ó´ÓÄÚ´ćÖжÁȡÎÄĽţÄÚČÝŁ¬Í¨ąý˝«Őű¸ö»ň˛ż·ÖÎÄĽţÓłÉäµ˝Äڴ棬ÓɲŮ×÷ϵͳŔ´´¦ŔíĽÓÔŘÇëÇóşÍĐ´ČëÎÄĽţŁ¬Ó¦ÓĂÖ»ĐčŇŞşÍÄÚ´ć´ň˝»µŔŁ¬ŐâĘąµĂIO˛Ů×÷·ÇłŁżěˇŁ
MmapÄÚ´ćÓłÉäşÍĆŐͨ±ę׼IO˛Ů×÷µÄ±ľÖĘÇř±đÔÚÓÚËü˛˘˛»ĐčŇŞ˝«ÎÄĽţÖеÄĘýľÝĎČż˝±´ÖÁOSµÄÄÚşËIO»şłĺÇřŁ¬¶řĘÇżÉŇÔÖ±˝Ó˝«ÓĂ»§˝řłĚË˝ÓеŘÖ·żŐĽäÖеÄŇ»żéÇřÓňÓëÎÄĽţ¶ÔĎó˝¨Á˘ÓłÉäąŘϵŁ¬ŐâŃůłĚĐňľÍşĂĎńżÉŇÔÖ±˝Ó´ÓÄÚ´ćÖĐÍęłÉ¶ÔÎÄĽţ¶Á/Đ´˛Ů×÷Ň»ŃůˇŁ
ByteBufferµÄŐýČ·ĘąÓĂ·˝Ę˝
- ĎňbufferÖĐĐ´ČëĘýľÝŁ¬ŔýČç
channel.read(buf) - µ÷ÓĂ
flip()ÇĐ»»łÉ¶ÁÄŁĘ˝ - ´ÓbufferÖжÁȡĘýľÝŁ¬ŔýČç
buffer.get() - µ÷ÓĂ
clear()»ňcompact()ÇĐ»»ÎŞĐ´ÄŁĘ˝ - Öظ´1-4
µă»÷˛éż´´úÂë
@Slf4j
public class TestByteBuffer {
public static void main(String[] args) {
try (FileInputStream fileInputStream = new FileInputStream("data.txt");
FileChannel channel = fileInputStream.getChannel()) {
ByteBuffer buffer = ByteBuffer.allocate(10);
while (true) {
int len = channel.read(buffer);
if (len < 0) {
break;
}
log.info("¶Áµ˝µÄ×Ö·űĘýŁş{}", len);
buffer.flip();
while (buffer.hasRemaining()) {
byte b = buffer.get();
log.info("¶Áµ˝µÄ×Ö·űŁş{}", (char) b);
}
buffer.clear();
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
Javaąć¶¨ÄÚÂëĘąÓĂUTF-16±ŕÂ룬һ¸ö×Ö·űŐĽÓĂ2¸ö×Ö˝ÚŁ¬Ň˛ľÍĘÇJavaÖеÄcharŔŕĐÍÔÚÄÚ´ćÖĐĘÇĘąÓĂUTF-16µÄ±ŕÂëĐÎĘ˝´ć´˘µÄˇŁ¶řÎŇĂÇ´úÂëÖжÁȡµÄÎÄĽţdata.txtĘąÓõÄĘÇUTF-8±ŕÂë¸ńĘ˝Ł¬Ňň´Ë¶ÔÓÚĆäÖеÄÓ˘ÎÄ×Ö·űşÍĘý×ÖŁ¬Ň»¸ö×Ö·űÖ»ŐĽÓĂŇ»¸ö×Ö˝ÚˇŁŇň´Ë´úÂëÖĐÎŇĂÇżÉŇÔĂż´Î¶Áȡһ¸ö×Ö˝ÚŁ¬Č»şóÔŮ°ŃËüת»»łÉJavaÄÚ˛żµÄcharˇŁ
BufferµÄ˝áąą
BufferĘÇÓÉĚض¨»ů±ľŔŕĐ͵ÄÔŞËŘ×éłÉµÄĎßĐÔÓĐĎŢĐňÁĐŁ¬łýÁËBufferŔďĂćµÄÄÚČÝŁ¬Ćä×îÖŘŇŞµÄĘôĐÔľÍĘÇËüµÄcapacityŁ¬limitşÍpositionˇŁ
capacityŁşBufferÖĐżÉŇÔ´˘´ćµÄÔŞËŘĘýÁżŁ¬BufferµÄcapacity˛»ÄÜÎŞ¸şÖµŇ˛ÓŔÔ¶˛»»á¸Ä±äˇŁlimitŁşBufferÖеÚŇ»¸ö˛»Äܱ»¶Áȡ»ňĐ´ČëµÄÔŞËصÄλÖĂŁ¬limit˛»ÄÜÎŞ¸şÖµŇ˛˛»ÄÜ´óÓÚcapacityˇŁpositionŁşBufferÖĐĎÂŇ»¸ö˝«Ňޱ»¶Áȡ»ňĐ´ČëµÄÔŞËصÄλÖĂŁ¬position˛»ÄÜÎŞ¸şÖµŇ˛˛»ÄÜ´óÓÚlimitˇŁ