Ъ§зщКЭЧаЦЌЪЧ Go гябджаГЃМћЕФЪ§ОнНсЙЙЃЌКмЖрИеИеЪЙгУ Go ЕФПЊЗЂепЭљЭљЛсЛьЯ§етСНИіИХФюЃЌЪ§зщзїЮЊзюГЃМћЕФМЏКЯдкБрГЬгябджаЪЧЗЧГЃживЊЕФЃЌГ§СЫЪ§зщжЎЭтЃЌGo гябдв§ШыСЫСэвЛИіИХФю ЁЊ ЧаЦЌЃЌЧаЦЌгыЪ§зщгавЛаЉРрЫЦЃЌЕЋЪЧЫќУЧЕФВЛЭЌжЎДІЕМжТЪЙгУЩЯЛсВњЩњОоДѓЕФВюБ№ЁЃ
етРяЮвУЧНЋДг Go гябд БрвыЦкМф ЕФЙЄзїКЭдЫааЪБРДНщЩмЪ§зщвдМАЧаЦЌЕФЕзВуЪЕЯждРэЃЌЦфжаЛсАќРЈЪ§зщЕФГѕЪМЛЏвдМАЗУЮЪЁЂЧаЦЌЕФНсЙЙКЭГЃМћЕФЛљБОВйзїЁЃ
Ъ§зщ
Ъ§зщЪЧгЩЯрЭЌРраЭдЊЫиЕФМЏКЯзщГЩЕФЪ§ОнНсЙЙЃЌМЦЫуЛњЛсЮЊЪ§зщЗжХфвЛПщСЌајЕФФкДцРДБЃДцЪ§зщжаЕФдЊЫиЃЌЮвУЧПЩвдРћгУЪ§зщжадЊЫиЕФЫїв§ПьЫйЗУЮЪдЊЫиЖдгІЕФДцДЂЕижЗЃЌГЃМћЕФЪ§зщДѓЖрЖМЪЧвЛЮЌЕФЯпадЪ§зщЃЌЖјЖрЮЌЪ§зщдкЪ§жЕКЭЭМаЮМЦЫуСьгђШДгаБШНЯГЃМћЕФгІгУЁЃ
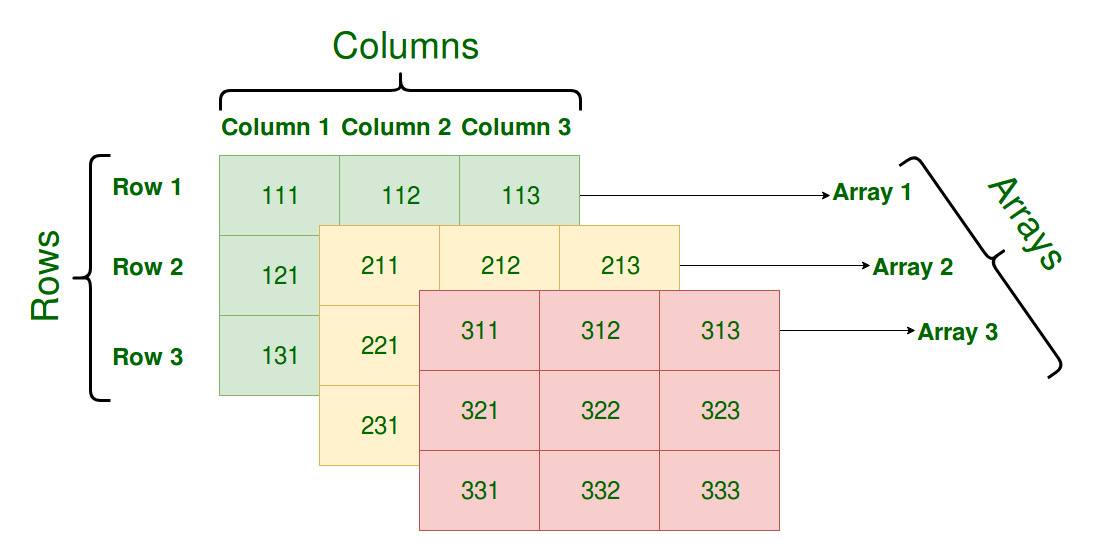
Ъ§зщзїЮЊвЛжжЪ§ОнРраЭЃЌвЛАуЧщПіЯТгЩСНВПЗжзщГЩЃЌЦфжавЛВПЗжБэЪОСЫЪ§зщжаДцДЂЕФдЊЫиРраЭЃЌСэвЛВПЗжБэЪОЪ§зщзюДѓФмЙЛДцДЂЕФдЊЫиИіЪ§ЃЌGo гябдЕФЪ§зщРраЭвЛАуЪЧетбљЕФЃК
[10]int
[200]interface{}Go гябджаЪ§зщЕФДѓаЁдкГѕЪМЛЏжЎКѓОЭЮоЗЈИФБфЃЌЪ§зщДцДЂдЊЫиЕФРраЭЯрЭЌЃЌЕЋЪЧДѓаЁВЛЭЌЕФЪ§зщРраЭдк Go гябдПДРДвВЪЧЭъШЋВЛЭЌЕФЃЌжЛгаСНИіЬѕМўЖМЯрЭЌВХЪЧЭЌвЛИіРраЭЁЃ
func NewArray(elem *Type, bound int64) *Type {
if bound < 0 {
Fatalf("NewArray: invalid bound %v", bound)
}
t := New(TARRAY)
t.Extra = &Array{Elem: elem, Bound: bound}
t.SetNotInHeap(elem.NotInHeap())
return t
}БрвыЦкМфЕФЪ§зщРраЭ Array ОЭАќКЌСНИіНсЙЙЃЌвЛИіЪЧдЊЫиРраЭ ElemЃЌСэвЛИіЪЧЪ§зщЕФДѓаЁЩЯЯо BoundЃЌетСНИізжЖЮЙЙГЩСЫЪ§зщРраЭЃЌЖјЕБЧАЪ§зщЪЧЗёгІИУдкЖбеЛжаГѕЪМЛЏвВдкБрвыЦкМфОЭШЗЖЈСЫЁЃ
ДДНЈ
Go гябджаЕФЪ§зщгаСНжжВЛЭЌЕФДДНЈЗНЪНЃЌвЛжжЪЧЮвУЧЯдЪНжИЖЈЪ§зщЕФДѓаЁЃЌСэвЛжжЪЧБрвыЦїЭЈЙ§дДДњТыздааЭЦЖЯЪ§зщЕФДѓаЁЃК
arr1 := [3]int{1, 2, 3}
arr2 := [...]int{1, 2, 3}КѓвЛжжЩљУїЗНЪНдкБрвыЦкМфОЭЛсБЛЁКзЊЛЛЁЛГЩЮЊЧАвЛжжЃЌЯТУцЮвУЧЯШРДНщЩмЪ§зщДѓаЁЕФБрвыЦкЭЦЕМЙ§ГЬЁЃ
ЩЯЯоЭЦЕМ
етСНжжВЛЭЌЕФЗНЪНЛсЕМжТБрвыЦїзіГіВЛЭЌЕФДІРэЃЌШчЙћЮвУЧЪЙгУЕквЛжжЗНЪН [10]TЃЌФЧУДБфСПЕФРраЭдкБрвыНјааЕН РраЭМьВщ НзЖЮОЭЛсБЛЭЦЖЯГіРДЃЌдкетЪББрвыЦїЛсЪЙгУ NewArray ДДНЈАќКЌЪ§зщДѓаЁЕФ Array РраЭЃЌЖјШчЙћЪЙгУ [...]T ЕФЗНЪНЃЌЫфШЛдкетвЛВНвВЛсДДНЈвЛИі Array РраЭ Array{Elem: elem, Bound: -1}ЃЌЕЋЪЧЦфжаЕФЪ§зщДѓаЁЩЯЯоЛсЪЧ -1 ЕФНсЙЙЃЌетвтЮЖзХЛЙашвЊКѓУцЕФ typecheckcomplit КЏЪ§ЭЦЕМИУЪ§зщЕФДѓаЁЃК
func typecheckcomplit(n *Node) (res *Node) {
// ...
switch t.Etype {
case TARRAY, TSLICE:
var length, i int64
nl := n.List.Slice()
for i2, l := range nl {
i++
if i > length {
length = i
}
}
if t.IsDDDArray() {
t.SetNumElem(length)
}
}
}етИіЩОМѕКѓЕФ typecheckcomplit КЏЪ§ЭЈЙ§БщРњдЊЫиРДЭЦЕМЕБЧАЪ§зщЕФГЄЖШЃЌЮвУЧФмПДГі [...]T РраЭЕФЩљУїВЛЪЧдкдЫааЪББЛЭЦЕМЕФЃЌЫќЛсдкРраЭМьВщЦкМфОЭБЛЭЦЖЯГіе§ШЗЕФЪ§зщДѓаЁЁЃ
гяОфзЊЛЛ
ЫфШЛ [...]T{1, 2, 3} КЭ [3]T{1, 2, 3} дкдЫааЪБЪЧЭъШЋЕШМлЕФЃЌЕЋЪЧетжжМђЖЬЕФГѕЪМЛЏЗНЪНвВжЛЪЧ Go гябдЮЊЮвУЧЬсЙЉЕФвЛжжгяЗЈЬЧЃЌЖдгквЛИігЩзжУцСПзщГЩЕФЪ§зщЃЌИљОнЪ§зщдЊЫиЪ§СПЕФВЛЭЌЃЌБрвыЦїЛсдкИКд№ГѕЪМЛЏзжУцСПЕФ anylit КЏЪ§жазіСНжжВЛЭЌЕФгХЛЏЃК
func anylit(n *Node, var_ *Node, init *Nodes) {
t := n.Type
switch n.Op {
case OSTRUCTLIT, OARRAYLIT:
if n.List.Len() > 4 {
vstat := staticname(t)
vstat.Name.SetReadonly(true)
fixedlit(inNonInitFunction, initKindStatic, n, vstat, init)
a := nod(OAS, var_, vstat)
a = typecheck(a, ctxStmt)
a = walkexpr(a, init)
init.Append(a)
break
}
fixedlit(inInitFunction, initKindLocalCode, n, var_, init)
// ...
}
}- ЕБдЊЫиЪ§СПаЁгкЛђепЕШгк 4 ИіЪБЃЌЛсжБНгНЋЪ§зщжаЕФдЊЫиЗХжУдкеЛЩЯЃЛ
- ЕБдЊЫиЪ§СПДѓгк 4 ИіЪБЃЌЛсНЋЪ§зщжаЕФдЊЫиЗХжУЕНОВЬЌЧјВЂдкдЫааЪБШЁГіЃЛ
ЕБЪ§зщЕФдЊЫиаЁгкЛђепЕШгкЫФИіЪБЃЌfixedlit ЛсИКд№дкКЏЪ§БрвыжЎЧАНЋХњСЫгяЗЈЬЧЭтвТЕФДњТызЊЛЛГЩдгаЕФбљзгЃК
func fixedlit(ctxt initContext, kind initKind, n *Node, var_ *Node, init *Nodes) {
var splitnode func(*Node) (a *Node, value *Node)
// ...
for _, r := range n.List.Slice() {
a, value := splitnode(r)
a = nod(OAS, a, value)
a = typecheck(a, ctxStmt)
switch kind {
case initKindStatic:
genAsStatic(a)
case initKindLocalCode:
a = orderStmtInPlace(a, map[string][]*Node{})
a = walkstmt(a)
init.Append(a)
default:
Fatalf("fixedlit: bad kind %d", kind)
}
}
}гЩгкДЋШыЕФРраЭЪЧ initKindLocalCodeЃЌЩЯЪіДњТыЛсНЋдгаЕФГѕЪМЛЏгяЗЈВ№ЗжГЩвЛИіЩљУїБфСПЕФгяОфКЭ N ИігУгкИГжЕЕФгяОфЃК
var arr [3]int
arr[0] = 1
arr[1] = 2
arr[2] = 3ЕЋЪЧШчЙћЕБЧАЪ§зщЕФдЊЫиДѓгк 4 ИіЪБЃЌanylit ЗНЗЈЛсЯШЛёШЁвЛИіЮЈвЛЕФ staticnameЃЌШЛКѓЕїгУ fixedlit КЏЪ§дкОВЬЌДцДЂЧјГѕЪМЛЏЪ§зщжаЕФдЊЫиВЂНЋСйЪББфСПИГжЕИјЕБЧАЕФЪ§зщЃК
func fixedlit(ctxt initContext, kind initKind, n *Node, var_ *Node, init *Nodes) {
var splitnode func(*Node) (a *Node, value *Node)
// ...
for _, r := range n.List.Slice() {
a, value := splitnode(r)
setlineno(value)
a = nod(OAS, a, value)
a = typecheck(a, ctxStmt)
switch kin