除。您只需将它们从.Trash复制或移动到原始位置即可恢复它们。
热门提示:您可以在不使用任何参数的情况下键入hdfs dfs,以获取可用命令的完整列表。
如果您更喜欢使用图形界面与HDFS交互,您可以查看免费和开源的HUE(Hadoop用户体验)。它包含一个方便的“文件浏览器”组件,允许您浏览HDFS文件和目录并执行基本操作。
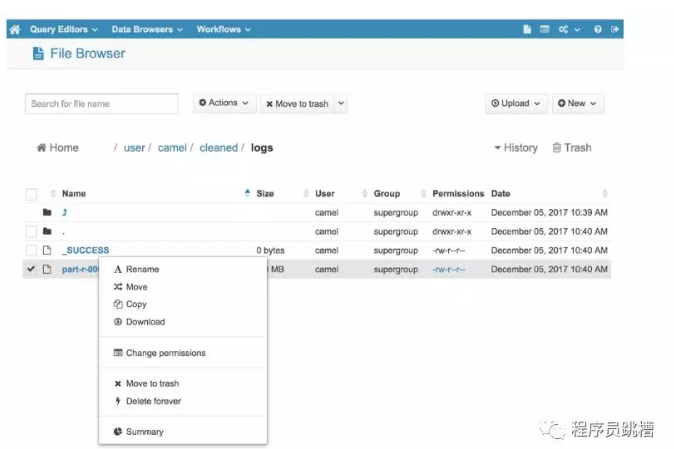
您还可以使用HUE通过“上传”按钮直接从计算机将文件上传到HDFS。
YARN(Yet Another Resource Negotiator)负责管理Hadoop集群上的资源,并支持运行处理存储在HDFS上的数据的各种分布式应用程序。
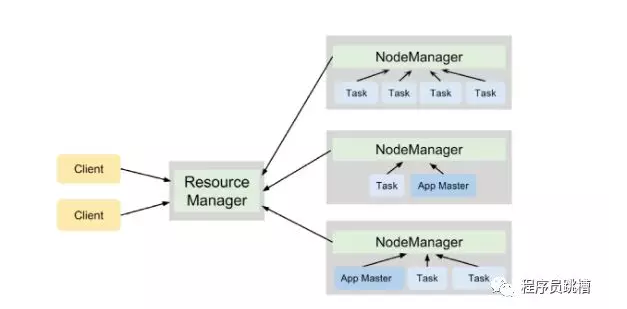
与HDFS类似,YARN遵循主从设计,ResourceManager进程充当主设备,多个NodeManager充当工作者。他们有以下责任:
的ResourceManager
节点管理器
YARN以资源容器的形式将集群资源分配给各种应用程序,资源容器表示RAM量和CPU核心数量的组合。
在YARN群集上执行的每个应用程序都有自己的ApplicationMaster进程。在群集上调度应用程序并协调此应用程序中所有任务的执行时,此过程开始。
图3说明了YARN守护程序在运行两个应用程序的4节点集群上的合作,这些应用程序总共产生了7个任务。
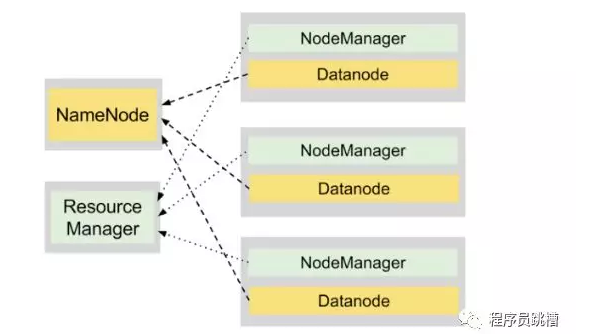
Hadoop = HDFS + YARN
在同一群集上运行的HDFS和YARN守护程序为我们提供了一个用于存储和处理大型数据集的强大平台。
DataNode和NodeManager进程在同一节点上并置以启用数据位置。这种设计使得能够在存储数据的机器上执行计算,从而最小化通过网络发送大块数据的必要性,这导致更快的执行时间。
YARN应用程序
YARN只是一个资源管理器,它知道如何将分布式计算资源分配给在Hadoop集群上运行的各种应用程序。换句话说,YARN本身不提供任何可以分析HDFS中数据的处理逻辑。因此,必须将各种处理框架与YARN集成(通过提供ApplicationMaster的特定实现)以在Hadoop集群上运行并处理来自HDFS的数据。
下面列出了最流行的分布式计算框架的简短描述,这些框架可以在由YARN支持的Hadoop集群上运行。
-
MapReduce - Hadoop的传统和最古老的处理框架,将计算表示为一系列map和reduce任务。它目前正被Spark或Flink等更快的引擎所取代。
-
Apache Spark - 一种用于大规模数据处理的快速通用引擎,可通过在内存中缓存数据来优化计算(后面部分将详细介绍)。
-
Apache Flink - 高吞吐量,低延迟的批处理和流处理引擎。它以其强大的实时处理大数据流的能力而着称。您可以在这篇全面的文章中找到Spark和Flink之间的差异:https://dzone.com/articles/apache-hadoop-vs-apache-spark
-
Apache Tez - 一个旨在加快Hive执行SQL查询的引擎。它可以在Hortonworks数据平台上获得,它将MapReduce替换为Hive的执行引擎。
监控YARN应用程序
可以使用ResourceManager WebUI跟踪在Hadoop集群上运行的所有应用程序的执行,默认情况下,该管理程序在端口8088上公开。
对于每个应用程序,您都可以阅读一些重要信息。
如果单击“ID”列中的条目,您将获得有关所选应用程序执行的更详细的指标和统计信息。
热门提示:使用ResourceManager WebUI,您可以检查可用于处理的RAM总量和CPU核心数以及当前的Hadoop集群负载。查看页面顶部的“群集指标”。
――――――――――――――――――――
推荐阅读:
老王讲架构:负载均衡
支付宝系统架构内部剖析
大数据Spark与Storm技术选型
【赞】用Python实现Zabbix-API 监控
程序员怎么留住健康?
大数据智慧平台技术方案
大数据聚合平台解决方案