的按照requestId+图片序号来获取banner图(每一个请求都会有一个请求的requestId,由于一次是5张图,所以图片是有序号的,可以轮询的获取),轮询获取时,就接口的API服务就可以直接去查询redis了,因为这样查询速度很快,用户体验会更好,图片就会类似实时查询一样,频繁的查询也不影响性能。其实你如果看过鹿班的话,你也会看到,他们的结果图也是分批出来,不是一次出来全部。

在第一轮上线后,由于用户使用体验还可以,给了更多的时间来做第二轮的产品迭代,所以到第二轮迭代时,我们为了支撑服务和其他更多的需求,对架构做了比较大的调整。
在第二轮迭代时,架构图就变成了这样
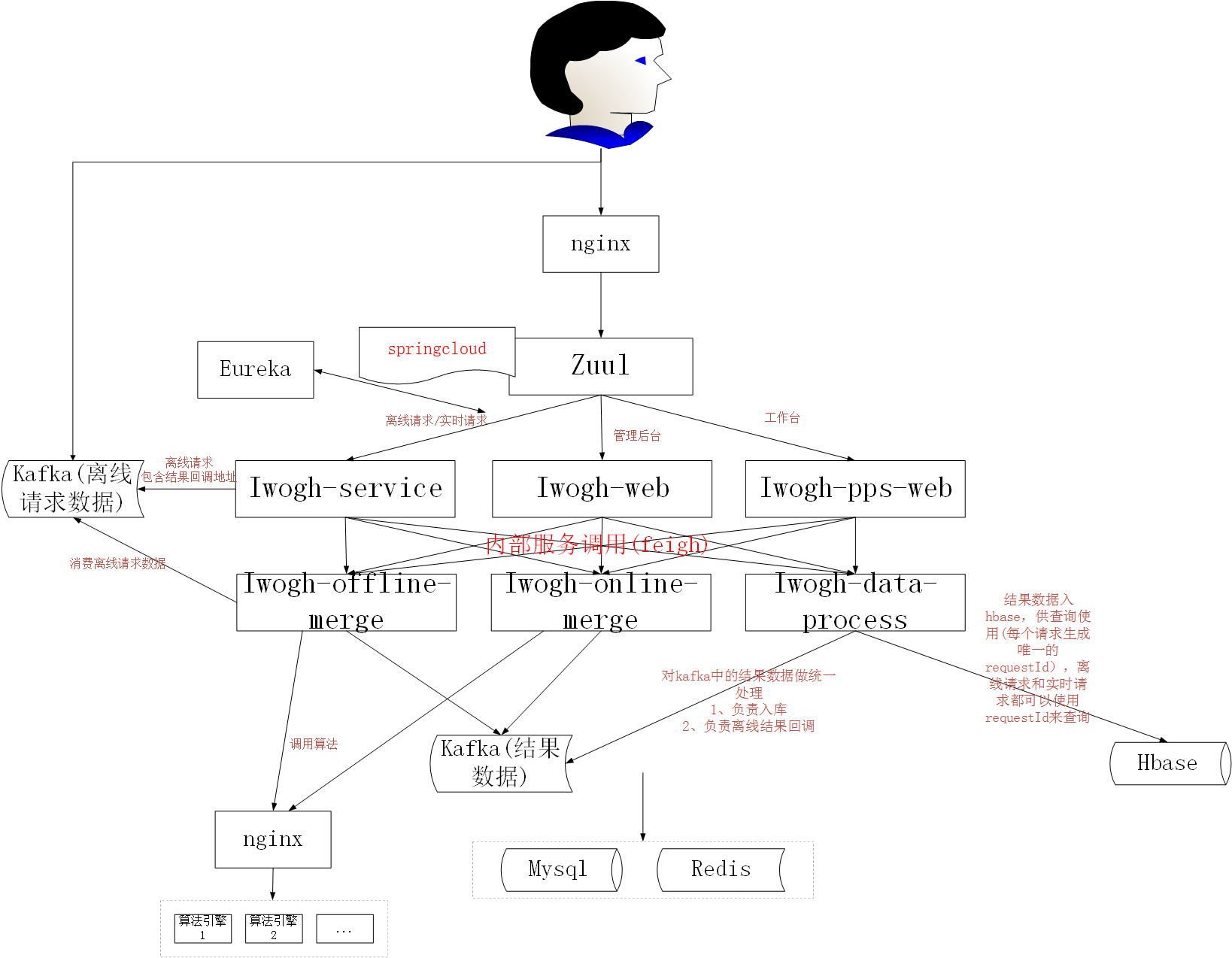
1、 我们需要支撑接口API服务了,包括实时服务,离线服务,供其他的业务来调用使用。初期API主要分这几种情况
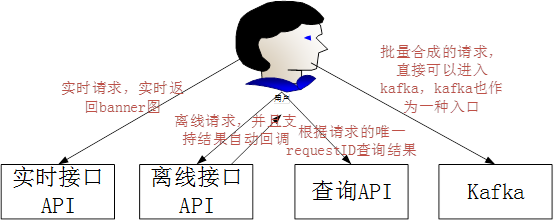
接口API的设计主要包括这几点
1)、客户端每次请求需要带入一个时间戳,服务端会校验这个时间戳,超过一定时间范围内的请求,服务端作为无效的请求自动丢弃,也可以避免接口服务被机器人进行攻击。
2)、每个请求需要带入一个Appid,这个Appid由平台自动分配。
3)、每个请求需要用一个秘钥来生成签名,生成的签名sign也是需要作为一个参数在接口中传入。 每个Appid会分配一个秘钥,这个秘钥是保密不公开的提供给用户。
4)、签名的生成会按照时间戳+appid,然后使用秘钥来生成签名。
5)、每次请求返回(不管实时还是离线),都会返回一个唯一的requestID给用户。用户可以用这个requestID来调用查询接口查询已经实时合成过的banner图,也可以查询离线合成的banner图。
2、在离线请求中,如果用户传入了回调的url地址,那么在离线处理完后,我们会自动进行回调,在设计时,我们特别做了考虑。
3、kafka也可以作为一个入口,比如大量的合成,用户可以直接推入到kafka中,因为通过http请求进行离线合成,还是会有非常大的请求消耗。
4、在架构图中,我们设计了
Iwogh-service:主要做接口API服务,不涉及逻辑处理,接收到的离线合成是,直接把请求放入到kafka中。
Iwogh-pps-web:用户工作台模块,包括智能合成和手动合成
Iwogh-web:后台管理模块,在第二轮迭代中,我们把工作台和后台管理进行了拆分,拆成了两个web服务,作为两个war包
Iwogh-offline-merge:负责离线合成处理,负责消费kafka中的离线请求数据,并且去调用算法服务处理,处理完的结果放入到新的kafka中。
Iwogh-online-merge:负责处理实时请求服务,去调用算法处理。并且负责工作台过来的banner图处理请求。处理完成的请求,统一发送到kafka中。
Iwogh-data-process:消费处理完成的kafka结果数据,负责结果数据的统一入库处理,以及离线请求的回调处理。
由于我们存储了所有的处理请求和结果,在这里,我们不是选用的mysql来存储这些数据,而是hbase,hbase很适用于我们的场景,由于requestId永远是唯一的,所以hbase的rowkey可以用requestId就可以了。
而且hbase支持batch查询,也就是一次可以传入多个requestId来进行查询,效率也是非常高。
5、我们使用springcloud中的Zuul来作为我们的接口服务请求中的sign签名认证校验,Zuul非常适合这种场景。
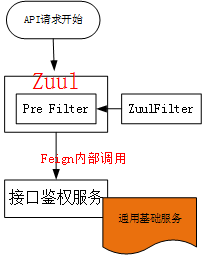
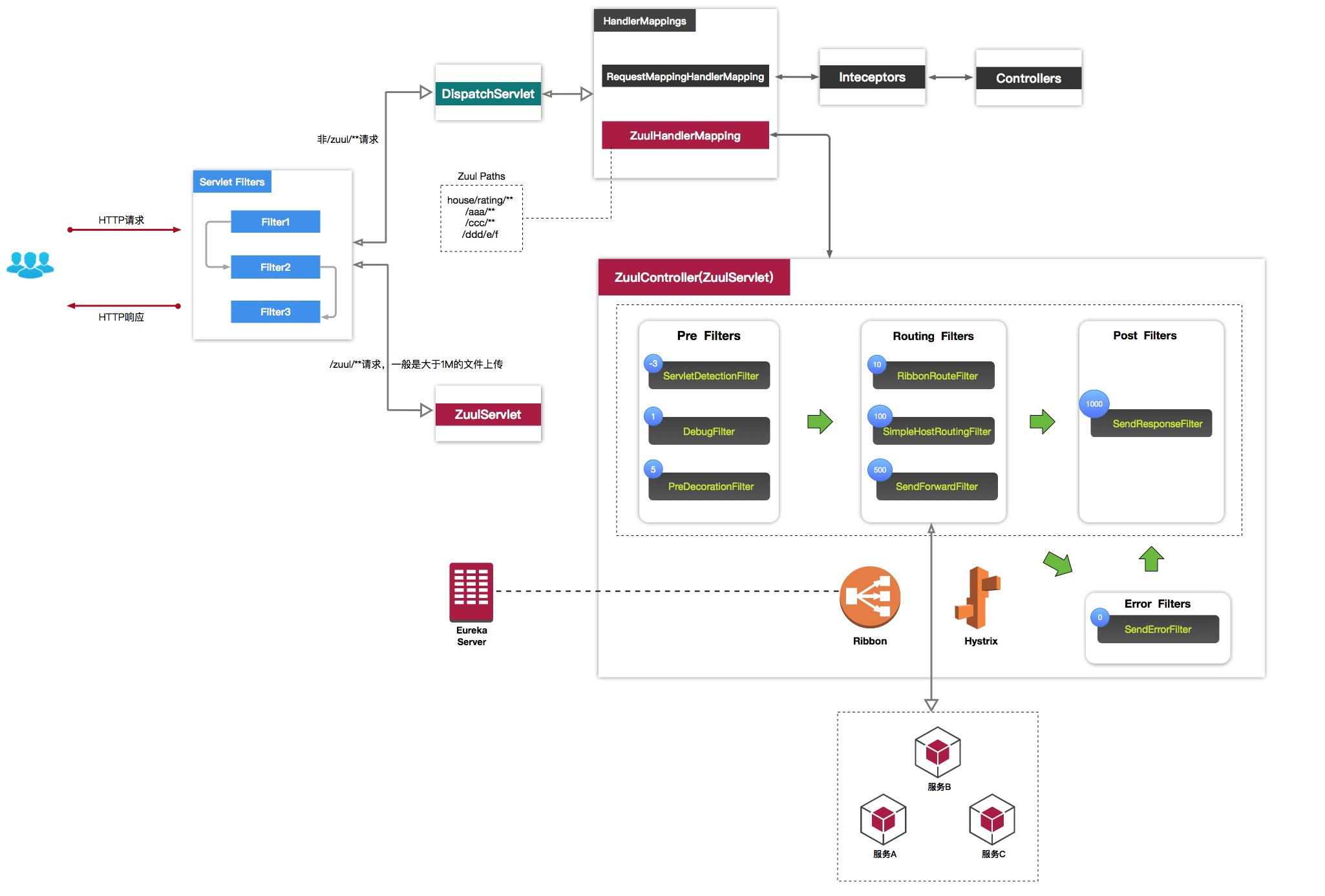
如果对于Zuul不熟悉,可以参考服务网关组件Zuul工作原理流程如下:
未完待续,请继续关注