串联所有的历史版本。假设该记录被tx_id为68、80、90、100的四个事务修改了四次,该数据就有四个版本,通过rollback_ptr从新到旧串联起来。
然后,三个历史版本分别被其他不同的事务读取。为什么会出现不同的事务读取到不同的版本呢?因为T1、T2最先,此时历史版本3是最新的,还没有历史版本1、2;之后该记录被修改,产生了历史版本2,然后出现了T3;之后该记录又被修改,产生了历史版本1,然后出现了T4。每个事务读取的都是这个事务执行时最新的历史版本。
这些历史版本什么时候可以删除呢?在T1、T2提交之后,历史版本3就可以删除了;在T3提交之后,历史版本2就可以删除了,依此类推。
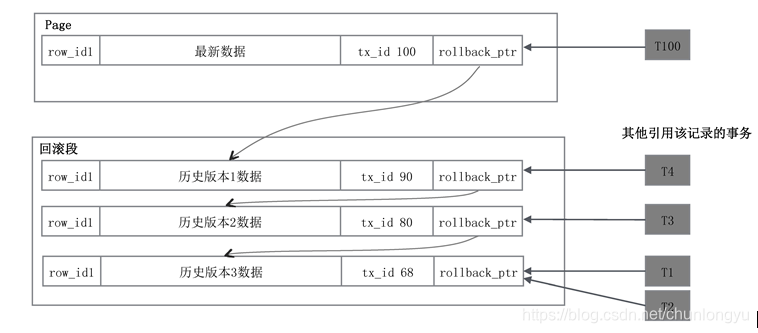
图6-18 Undo Log逻辑结构
注意:在这里有一个专业名词,叫“回滚段”,很多描述Undo Log的文章花大篇幅描述它。但本书作者不想解释这个名词,因为它不仅不会帮助我们对原理的理解,还会把简单问题复杂化。说得通俗一点,就是修改记录之前先把记录拷贝一份出来,然后拷贝出来的这些历史版本形成一个链表,仅此而已。
6.6.4 Undo Log与Redo Log的关联
Undo Log本身也要写入磁盘,但一个事务修改多条记录,产生多条Undo Log,不可能同步写入磁盘,所以遇到了开篇讲Write-Ahead时的问题。如何解决Undo Log需要多次写入磁盘的效率问题呢?
Redo Log记录的是对数据的修改,凡是对数据的修改,都必须记入Redo Log。可以把Undo Log也当作数据!在内存中记录Undo Log,异步地刷盘,宕机重启,用Redo Log恢复Undo Log。
拿一个事务来举例:
start transaction update表1某行记录 delete表1某行记录 insert表2某行记录 commit
把Undo Log和Redo Log加进去,此事务类似下面伪代码所示:
start transaction 写Undo Log1: 备份该行数据(update) update表1某行记录 写Redo Log1 Undo Log2:备份该行数据(insert) delete 表1某行记录 写Redo Log2 Undo Log3:该行的主键ID(delete) insert表2某行记录 写Redo Log3 commit
在这里,所有Undo Log和Redo Log的写入都可以只在内存中进行,只要保证Commit之后Redo Log落盘即可,Undo Log可以一直保留在内存里,之后异步刷盘。
文章太长,未完待续,接下来的1篇,会继续分析Undo Log。