意义就像它的名字,会根据索引词的频率来计算,索引词出现的次数越多,分数越高。
例子如下:
搜索hello
有两份文档:A文档:hello world!,B文档:hello hello hello
结果是B文档的score大于A文档。
搜索hello world
有两份文档:A文档:hello world!,B文档:hello,are you ok?
结果是A文档的score大于B文档。
要根据索引词来综合考虑。
IDF算法
IDF算法全称Inverse Document Frequency,逆文本频率。
搜索文本的词在整个索引的所有文档中出现的次数越多,这个词所占的score的比重就越低。
例子如下:
搜索hello world,其中索引中hello出现次数1000次,world出现100次。
有三份文档:A文档hello,are you ok?,B文档The world is interesting!,C文档hello world!
结果是:C>B>A
由于hello出现频率高,所以单个hello得到的score比不上world。
Field-length norm算法。
- 这个算法elasticsearch并没有单独列出来,但也有生效。
- field越长,相关度就越低,数据长度会拉低相关度。
例子如下:
搜索hello world!
有两份文档:A文档hello world!,B文档hello world,I'm xxx!
结果是:A>B
三种算法的综合:
(下面属于理论分析,并不真实这样计算)
TF算法针对在Field中,索引词出现的频率;
IDF算法针对在整个索引中的索引词出现的频率;
Field-length norm算法针对Field的长度。
那么可以这样分析,由于Field-length norm算法并不直接针对score,所以它是最后起作用的,它理论上类似于一个除数。而TF和IDF是平等的,IDF计算出每一个索引词的score量,TF来计算整个文档中索引词的score的加和。
也就是如下的计算:
1.IDF:计算索引词的单位score,比如hello=0.1,world=0.2,
2.TF:计算整个文档的sum(score),hello world!I'm xxx.得到0.1+0.2=0.3
3.Field-length norm:将sum(score)/对应Field的长度,得出的结果就是score。
score计算API
elasticsearch提供了测试计算score的API,语法类似如下:
GET /index/type/_search?explain=true
{
"query": {
"match": {
"搜索字段": "搜索值"
}
}
}
例子:
GET /douban/book/_search?explain=true
{
"query": {
"match": {
"book_name": "Story"
}
}
}
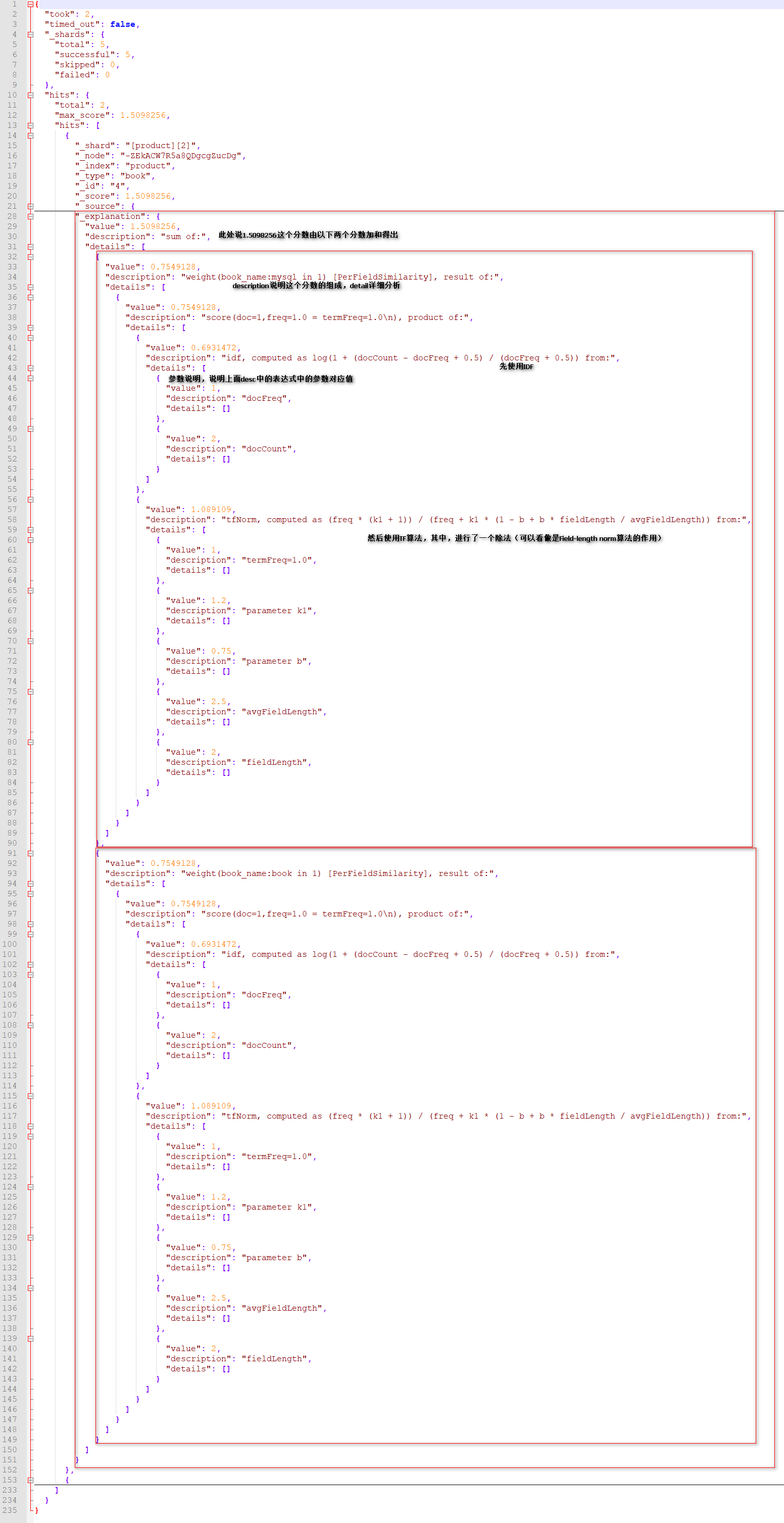
返回结果数据解析:
_explanation是score的原因,_explanation的格式是先列出分数,然后detail部分解释分数,内层也是。
小节总结
这节介绍了相关度分数的计算方式,可以大致了解一下score是怎么得出来得,TF是索引词频率算法,是对索引词分数的加和;IDF是基于整个索引对每个索引词的计算分数;Field-length用于降低数据长的文档的相关度分数。
分词器
什么是分词器?
分词器负责对document进行处理,以提高搜索效率。
分词器通常由分解器tokenizer和词元过滤器token filter组成。
分词器对数据的分词处理:为了提高索引的效率,ElasticSearch会数据进行处理,处理方式主要有字符过滤、词转换、词拆分
字符过滤:过滤一些特殊字符,例如&、||、html标签,因为这些词通常搜索意义不大。
词转换:把一些意义相同的词统一转成一个词,(同词义转换)比如mom,mother统一转成mom;(大小写转换)he,He统一归为He;还处理一些词意义不大的词(停用词清除),比如英文的“the”,“to”,这些词使用频率很高,但没有具体意义。
词拆分:进行数据的拆分,拆分成词,比如把good morning,mom拆分成good,morining,mom。另外,词拆分并不完全是按照数据的最小单位分解的,某一些分词器会把一些词进行组合,因为一些词的组合起来才有索引的意义,比如中文的一些词通常要组合起来才有意义,比如“大”和“家”要组成“大家”才有比较具体的意义,这是为了确保索引词的最小单位是有意义的(比如英文mom的最小单位是m,o,m,内部的分词器要能够区分出mom整个是有意义的才可以确保是采用mom作为索引,而不是采用m和o,也正是因为这个问题,所以英文分词器不能用于中文分词器)。【分词器有很多个,默认的分词器是不能适当对中文数据分词的,它只能把一个个数据按最小的单位拆分,因为英文分词器不能分清楚怎么把词拆分才有意义,由于配置分词器是一个较为靠后的知识点,所以前期将以英文数据为测试数据。】
常见的内置分词器:
每一个分词器的都有一些自己的规则,比如一些分词器会把a当成停用词,有些则不会;有些分词器会去掉标点符号,有些则不会;有些分词器能识别英文词,但识别不了中文词。要按需要来选择分词器。
- 标准分词器standard analyzer:最基础的分词器。可以把词进行拆分、
- 简单分词器simple analyzer:分词、做字符过滤、不做词转换。
- 空格分词器whitespace analyzer:仅仅根据空格来划分词,不会做字符过滤也不会做词转换。
- 英文分词器english:根据英文标准来分词,进行字符过滤,进行词转换(去除英文中的停用词(a,the),同义词转换等)
- 小写lowercase tokenizer:把英文全转成小写再分词
- 字母分词器letter tokenizer:根据字母来分词
分词示例
可以使用下面的格式的命令来测试不同分词器的分词效果:
GET /_analyze
{
"analyzer": "分词器",
"text": "要测试的文本"
}
// 举例:
GET /_analyze
{
"analyzer": "simple",
"text": "I am a little boy,I have 5$.dogs,long-distance,<html></html>"
}
示例:
原句:I am a little boy,I have 5$.dogs,long-distance,<html></html>
- 标准分词器standard analyzer:
i,am,a,little,boy,i,have,5,dogs,long,distance,html,html 【对于拆分成同一个词的,会形成同一个索引词】【这个分词器,