tions);
executorService.writeAsync(configName, StringCodec.INSTANCE,
new RedisCommand<Void>("HMSET", new VoidReplayConvertor()), configName,
"size", size, "hashIterations", hashIterations,
"expectedInsertions", expectedInsertions, "falseProbability", BigDecimal.valueOf(falseProbability).toPlainString());
try {
executorService.execute();
} catch (RedisException e) {
}
return true;
}

Redisson ��¡��������ʼ����ʱ�ᴴ��һ�� Hash ���ݽṹ�� key ���洢��¡��������4���������ԡ�
��ô Redisson ��¡��������α���Ԫ���� ��
public boolean add(T object) {
long[] hashes = hash(object);
while (true) {
int hashIterations = this.hashIterations;
long size = this.size;
long[] indexes = hash(hashes[0], hashes[1], hashIterations, size);
CommandBatchService executorService = new CommandBatchService(commandExecutor);
addConfigCheck(hashIterations, size, executorService);
//���� bitset ���� Ȼ�����setAsync�������÷����IJ�����������
RBitSetAsync bs = createBitSet(executorService);
for (int i = 0; i < indexes.length; i++) {
bs.setAsync(indexes[i]);
}
try {
List<Boolean> result = (List<Boolean>) executorService.execute().getResponses();
for (Boolean val : result.subList(1, result.size()-1)) {
if (!val) {
return true;
}
}
return false;
} catch (RedisException e) {
}
}
}
��Դ���У����Ƿ��� Redisson ��¡�����������Ķ����� λͼ��bitMap�� ��
�� Redis �У�λͼ�������� string �������ͣ�Redis ��һ���ַ������͵�ֵ����ܴ洢 512 MB �����ݣ�ÿ���ַ����ɶ���ֽ���ɣ�ÿ���ֽ����� 8 �� Bit λ��ɡ�λͼ�ṹ����ʹ�á�λ����ʵ�ִ洢�ģ���ͨ��������λ����Ϊ 0 �� 1���ﵽ���ݴ�ȡ��Ŀ�ģ����洢����Ϊ 2^32 �����ǿ���ʹ��getbit/setbit�������������λ���顣
Ϊ�˷��������⣬������һ���IJ��ԡ�
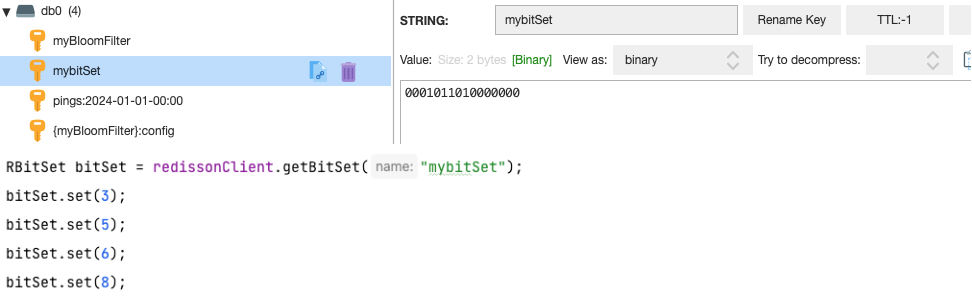
ͨ�� Redisson API ���� key Ϊ mybitset �� λͼ ���������� 3 ��5��6��8 λΪ 1 ���Ҳ��������ֵҲ��ȫƥ�䡣
4 ʵսҪ��
ͨ�� Guava �� Redisson ������ʹ�ò�¡�������Ƚϼ�������������ʵս�����ע�����
1�����洩����
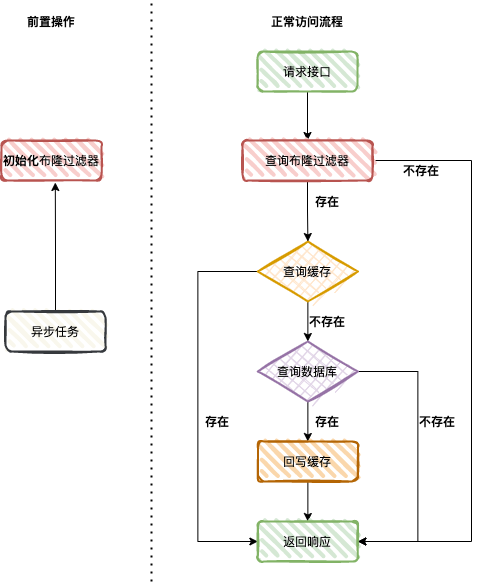
����������Ҫ��ʼ����¡��������Ȼ���û�����ʱ���жϹ��������Ƿ������Ԫ�أ�����������Ԫ�أ���ֱ�ӷ��ز����ڡ�
��������ӻ����в�ѯ���ݣ���������Ҳû�У����ѯ���ݿⲢ��д�����������ǰ�˷��ء�
2��Ԫ��ɾ������
��ʵ������Ԫ�ز�������ֻ�����ӣ�������ɾ��Ԫ�صij���������˵��Ʒ��ɾ����
ԭ��������һ�ڣ������Ѿ�֪������¡��������ʵ����֧��ɾ��Ԫ�أ���Ϊ���Ԫ�ؿ��ܹ�ϣ��һ����¡��������ͬһ��λ�ã����ֱ��ɾ����λ�õ�Ԫ�أ����Ӱ������Ԫ�ص��ж���
���������ַ�����
��������¡������
������������Counting Bloom Filter���Dz�¡����������չ���� Bloom Filter λ�����ÿһλ��չΪһ��С�ļ�������Counter�����ڲ���Ԫ��ʱ����Ӧ�� k ��k Ϊ��ϣ������������ Counter ��ֵ�ֱ�� 1��ɾ��Ԫ��ʱ����Ӧ�� k �� Counter ��ֵ�ֱ�� 1��
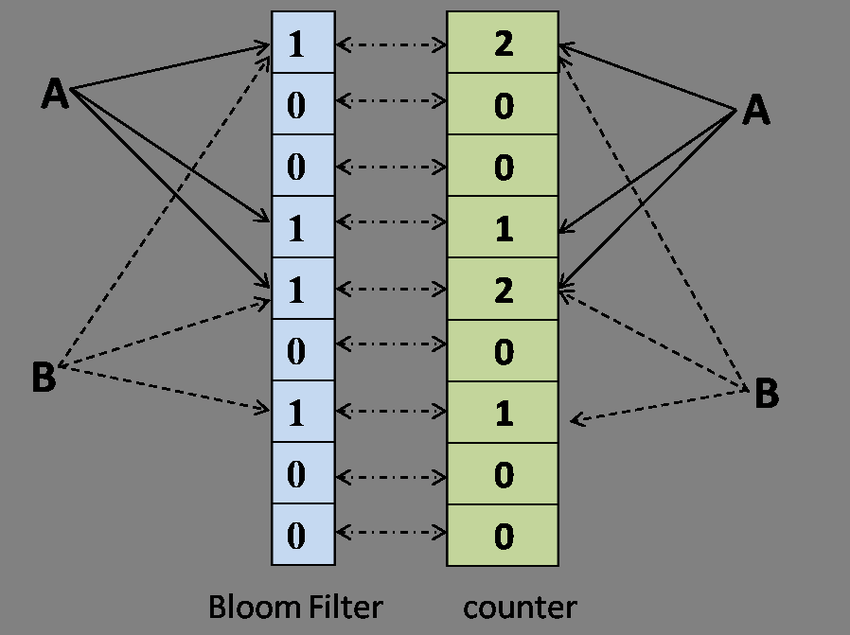
��Ȼ������¡���������Խ����¡��������ɾ��Ԫ�ص����⣬��������������һ�����⣺���������Դռ�ã������ںܶ�ʱ�����ɼ���Ŀռ��˷�����
�� ��ʱ���¹�����¡������
�ӹ��̽Ƕ���������ʱ���¹�����¡�����������������Ҳ�ɿ���ͬʱҲ��Լ�
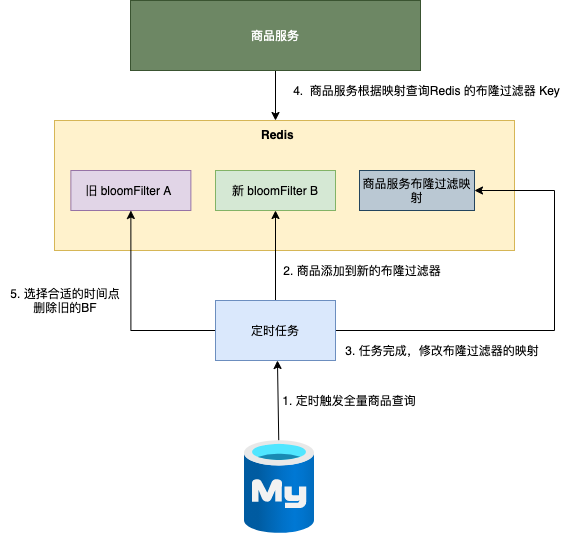
- ��ʱ����ȫ����Ʒ��ѯ ;
- ����Ʒ������ӵ��µIJ�¡������ ;
- ������ɣ�����Ʒ��¡��������ӳ�䣨�Ӿ� A �ij� �� B ��;
- ��Ʒ������ݲ�¡��������ӳ�䣬ѡ���µIJ�¡������ B������صIJ�ѯ���� ��
- ѡ����ʵ�ʱ��㣬ɾ���ɵIJ�¡������ A��
5 �ܽ�
��¡��������һ���ܳ���������������һϵ�����ӳ�亯������������һ��Ԫ���Ƿ���һ����������
�����ռ�Ч������ѯʱ����ԶԶ����һ����㷨��������һ���������� ���������� true , ��ζ��Ԫ�ؿ��ܴ��ڣ��������� false ��Ԫ�رض������ڣ���
��¡���������ĸ��������ԣ�
-
k : ��ϣ��������
-
m : λ���鳤��
-
n : �����Ԫ�ظ���
-
p : ������
Java ������ ��ͨ�� Guava �� Redisson ������ʹ�ò�¡�������dz���
��¡��������ɾ��Ԫ�أ������ǿ���ͨ��������¡����������ʱ���¹�����¡���������ַ���ʵ��ɾ��Ԫ�ص�Ч����
Ϊʲô��ô��Ŀ�Դ��Ŀ��ʹ�ò�¡������ ��
��Ϊ������ƾ����Ҽ�࣬������ʵ�ַdz����ף�Ч�ܸߣ���Ȼ��һ���������ʣ���������Ʋ�����Ҫ trade off �� ��
�ο����ϣ�
https://hackernoon.com/probabilistic-data-structures-bloom-filter-5374112a7832
����ҵ����¶������������������æ���ޡ��ڿ���ת��һ�£����֧�ֻἤ��������������������£��dz���л��
