��¡��������һ�����ɶ��Ҿ�������ݽṹ��
�����û�뵽�� RocketMQ�� Hbase ��Cassandra ��LevelDB ��RocksDB ��Щ֪����Ŀ�ж��в�¡����������Ӱ��
���ں�˳���Ա������ѧϰ�����Ⲽ¡�������кܴ�ı�Ҫ�ԡ����ɣ�����һ��Ʒζ��¡�����������֮����

1 ���洩
����������һ����Ʒ�����ѯ����Ľӿڣ�
public Product queryProductById (Long id){
// ��ѯ����
Product product = queryFromCache(id);
if(product != null) {
return product ;
}
// �����ݿ��ѯ
product = queryFromDataBase(id);
if(product != null) {
saveCache(id , product);
}
return product;
}
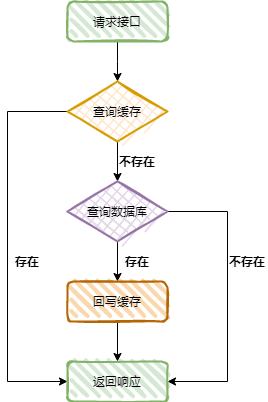
�������Ʒ�Ȳ��洢�ڻ����У�Ҳ���������ݿ��У���û�а취��д������������������������������ʷ���ʱ�����ݿ��ѹ���ͻἫ��
����һ�����͵Ļ��洩�ij�����
Ϊ�˽����������أ�ͨ�����ǿ�����ֲ�ʽ������д��һ������ʱ��϶̵Ŀ�ֵռλ����������ռ�ý϶�Ĵ洢�ռ䣬�Լ۱Ȳ��㡣
����ı����ǣ�"����Լ�С�Ĵ��ۼ���һ��Ԫ���Ƿ���һ����������"
���ǵ�������¡�����������ˣ����������������ƽ���ʱ��Ϳռ�����ά����
2 ԭ������
��¡��������Ӣ�Bloom Filter����1970���ɲ�¡����ġ���ʵ������һ���ܳ���������������һϵ�����ӳ�亯����
��¡�������������ڼ���һ��Ԫ���Ƿ���һ�������С������ŵ����ռ�Ч������ѯʱ����ԶԶ����һ����㷨��ȱ������һ������ʶ���ʺ�ɾ�����ѡ�
��¡��������ԭ������һ��Ԫ�ر����뼯��ʱ��ͨ�� K ��ɢ�к��������Ԫ��ӳ���һ��λ�����е� K ���㣬��������Ϊ 1������ʱ������ֻҪ������Щ���Dz��Ƕ��� 1 �ͣ���Լ��֪����������û�����ˣ������Щ�����κ�һ�� 0��������Ԫ��һ��������������� 1����Ԫ���ܿ�������
����˵������һ������Ϊ m ��λ���鲢��ʼ������Ԫ��Ϊ 0���� k ��ɢ�к�����Ԫ�ؽ��� k ��ɢ������� len (m) ȡ��õ� k ��λ�ò��� m �ж�Ӧλ������Ϊ 1��
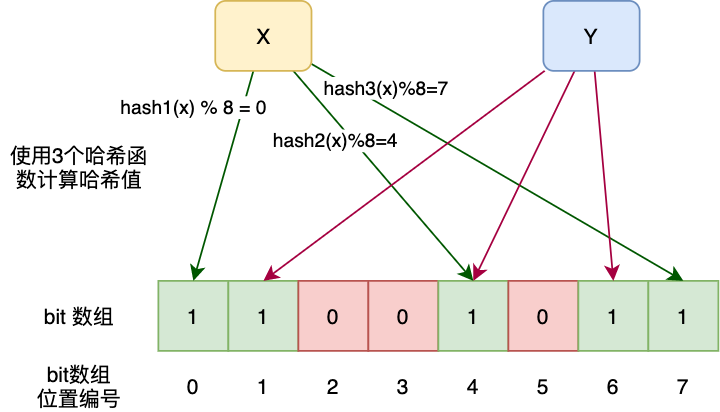
����ͼ��λ����ij����ǣ���ɢ�к��������� 3���Ⱥ�����Ԫ�أ�������������Ԫ�ض��������ι�ϣ��������������ϣֵ����ӳ�䵽λ����IJ�ͬ��λ�ã�����Ϊ1��Ԫ�� x ӳ�䵽λ����ĵڣ�λ���ڣ�λ���ڣ�λ��Ԫ�أ�ӳ�䵽�����λ����ĵڣ�λ���ڣ�λ���ڣ�λ��
����Ԫ�� x ��λ����ĵ�4λ������Ϊ1֮���ڴ���Ԫ�� y ʱ��4λ�ᱻ���ǣ�ͬ��Ҳ������Ϊ 1��
����¡�����������Ԫ��Խ��������Ϊ 1 �� bit λҲ��Խ��Խ����Ԫ�� x ����û�д洢���������ϣ����ӳ�䵽λ���������λ��������ֵ����Ϊ 1 �ˣ����ڲ�¡�������Ļ���������Ԫ�� x ���ֵҲ�Ǵ��ڵģ�Ҳ����˵��¡����������һ������������
�� ������
��¡���������������ĸ����ԣ�
-
k : ��ϣ��������
-
m : λ���鳤��
-
n : �����Ԫ�ظ���
-
p : ������
��λ���鳤��̫С��ᵼ������ bit λ�ܿ춼�ᱻ��Ϊ 1 ����ô��������ֵ���᷵�ء����ܴ��ڡ� �� �����˵�Ч���� λ���鳤��Խ����������ԽС��
ͬʱ����ϣ�����ĸ���Ҳ��Ҫ��������ϣ�����ĸ���Խ�������ٶȻ�Խ����������ҲԽС����֮����������Խ�ߡ�
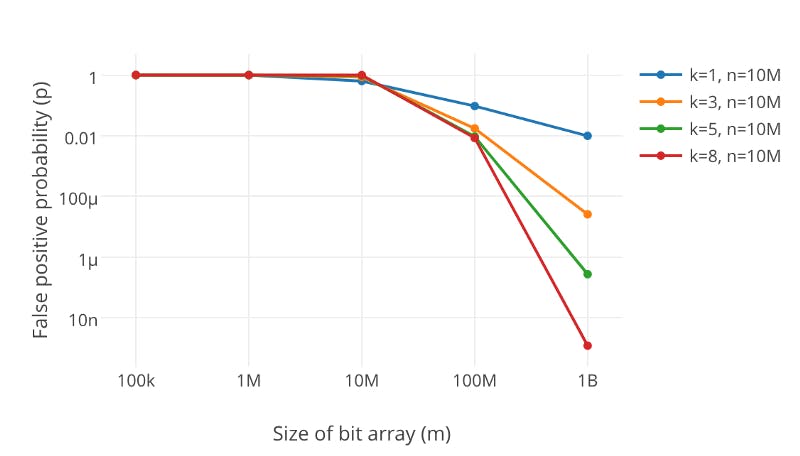
����ͼ���ǿ��Թ۲쵽��ͬλ���鳤�ȵ�����£����Ź�ϣ�����ĸ��˵��������������������½���
������ p �Ĺ�ʽ��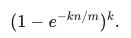
-
k �ι�ϣ����ijһ bit λδ����Ϊ 1 �ĸ���Ϊ
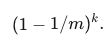
-
���� n ��Ԫ�غ�ijһ bit λ����Ϊ 0 �ĸ���Ϊ
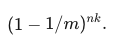
-
��ô���� n ��Ԫ�غ�ijһ bit λ��Ϊ1�ĸ���Ϊ
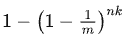
-
����������Ϊ
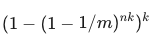 ���� m �㹻��ʱ�������ʻ�ԽС���ù�ʽԼ����
���� m �㹻��ʱ�������ʻ�ԽС���ù�ʽԼ����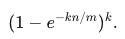
���ǻ�Ԥ����¡�������������� p �Լ��������Ԫ�ظ��� n �ֱ��Ƶ�������ʵ�λ���鳤�� m �� ��ϣ�������� k��
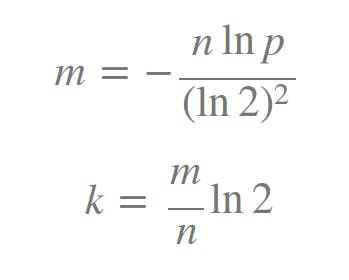
�� ��¡������֧��ɾ����
��¡��������ʵ����֧��ɾ��Ԫ�أ���Ϊ���Ԫ�ؿ��ܹ�ϣ��һ����¡��������ͬһ��λ�ã����ֱ��ɾ����λ�õ�Ԫ�أ����Ӱ������Ԫ�ص��жϡ�
�� ʱ��Ϳռ�Ч��
��¡�������Ŀռ临�Ӷ�Ϊ O(m) ������Ͳ�ѯʱ�临�Ӷȶ��� O(k) �� �洢�ռ�Ͳ��롢��ѯʱ�䶼������Ԫ�����Ӷ����� �ռ䡢ʱ��Ч�ʶ��ܸߡ�
����ϣ��������
Murmur3��FNV ϵ�к� Jenkins �ȷ�����ѧ��ϣ�����ʺϣ���Ϊ Murmur3 �㷨���ܹ�ƽ����ٶȺ�����ֲ����ܶԴ��Ʒ����ѡ������Ϊ��ϣ������
3 Guavaʵ��
Google Guava�� Google ������ά���Ŀ�Դ Java�����⣬��������������Ĺ����࣬�����ַ������������ϡ��������ߡ�I/O����ѧ�����ȵȡ�
1������Maven����
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre<</version>
</dependency>
2��������¡������
BloomFilter<Integer> filter = BloomFilter.create(
//Funnel ��һ���ӿڣ����ڽ��������͵Ķ���ת��Ϊ�ֽ�����
//�Ա����ڲ�¡�������Ĺ�ϣ���㡣
Funnels.integerFunnel(),
10000, // ����������Ŀ����
0.001 // ������
);
3����������
@PostConstruct
public void addProduct() {
logger.info("��ʼ����¡���������ݿ�ʼ");
//����4��Ԫ��
filter.put(1L);
filter.put(2L);
filter.put(3L);
filter.put(4L);
logger.info("��ʼ����¡���������ݽ���");
}
4���ж������Ƿ����
public boolean maycontain(Long id) {
return filter.mightContain(id);
}
�����������Dz鿴 Guava Դ���в�¡�����������ʵ�ֵ� ��
static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp, BloomFilter.Strategy strategy) {
// ʡ�Բ���ǰ����֤����
// λ���鳤��
long numBits = optimalNumOfBits(expectedInsertions, fpp);
// ��ϣ��������
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter<T>(
new LockFreeBitArray(numBits),
numHashFunctions,
funnel,
strategy
);
} c