逻辑
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
{
// 从 numa node cache 中获取到的空闲对象列表
void *freelist;
// slab cache 本地 cpu 缓存
struct kmem_cache_cpu *c = *pc;
// 分配对象所在的内存页
struct page *page;
// 尝试从指定的 node 节点缓存 kmem_cache_node 中的 partial 列表获取可以分配空闲对象的 slub
// 如果指定 numa 节点的内存不足,则会根据 cpu 访问距离的远近,进行跨 numa 节点分配
freelist = get_partial(s, flags, node, c);
if (freelist)
// 返回 numa cache 中缓存的空闲对象列表
return freelist;
// 流程走到这里说明 numa cache 里缓存的 slub 也用尽了,无法找到可以分配对象的 slub 了
// 只能向底层伙伴系统重新申请内存页(slub),然后从新的 slub 中分配对象
page = new_slab(s, flags, node);
// 将新申请的内存页 page (slub),缓存到 slab cache 的本地 cpu 缓存中
if (page) {
// 获取 slab cache 的本地 cpu 缓存
c = raw_cpu_ptr(s->cpu_slab);
// 刷新本地 cpu 缓存,将旧的 slub 缓存与 cpu 本地缓存解绑
if (c->page)
flush_slab(s, c);
// 将新申请的 slub 与 cpu 本地缓存绑定,page->freelist 赋值给 kmem_cache_cpu->freelist
freelist = page->freelist;
// 绑定之后 page->freelist 置空
// 现在新的 slub 中的空闲对象就已经缓存再了 slab cache 的本地 cpu 缓存中,后续就直接从这里分配了
page->freelist = NULL;
stat(s, ALLOC_SLAB);
// 将新申请的 slub 对应的 page 赋值给 kmem_cache_cpu->page
c->page = page;
*pc = c;
}
// 返回空闲对象列表
return freelist;
}
内核首先会在 get_partial 函数中找到我们指定的 NUMA 节点缓存结构 kmem_cache_node ,然后开始遍历 kmem_cache_node->partial 链表直到找到一个可供分配对象的 slab。然后将这个 slab 提升为 slab cache 的本地 cpu 缓存,并从 kmem_cache_node->partial 链表中依次填充 slab 到 kmem_cache_cpu->partial。
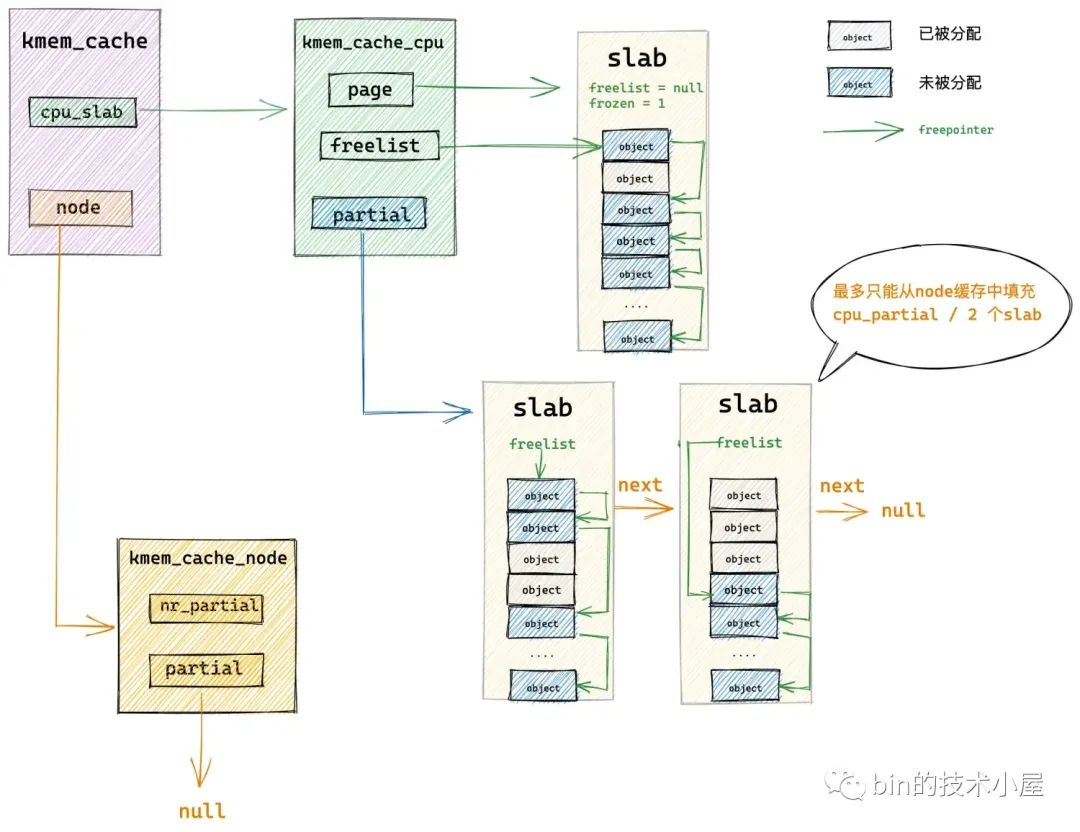
如果我们指定的 NUMA 节点 kmem_cache_node->partial 链表也是空的,随后内核就会跨 NUMA 节点进行查找,按照访问距离由近到远,开始查找其他 NUMA 节点 kmem_cache_node->partial 链表。
如果还是不行,最后就只能通过 new_slab 函数到伙伴系统中重新申请一个 slab,并将这个 slab 提升为本地 cpu 缓存。
3.2.1 从 NUMA 节点缓存 partial 链表中查找
static void *get_partial(struct kmem_cache *s, gfp_t flags, int node,
struct kmem_cache_cpu *c)
{
// 从指定 node 的 kmem_cache_node 缓存中的 partial 列表中获取到的对象
void *object;
// 即将要所搜索的 kmem_cache_node 缓存对应 numa node
int searchnode = node;
// 如果我们指定的 numa node 已经没有空闲内存了,则选取访问距离最近的 numa node 进行跨节点内存分配
if (node == NUMA_NO_NODE)
searchnode = numa_mem_id();
else if (!node_present_pages(node))
searchnode = node_to_mem_node(node);
// 从 searchnode 的 kmem_cache_node 缓存中的 partial 列表中获取对象
object = get_partial_node(s, get_node(s, searchnode), c, flags);
if (object || node != NUMA_NO_NODE)
return object;
// 如果 searchnode 对象的 kmem_cache_node 缓存中的 partial 列表是空的,没有任何可供分配的 slub
// 那么继续按照访问距离,遍历 searchnode 之后的 numa node,进行跨节点内存分配
return get_any_partial(s, flags, c);
}
get_partial 函数的主要内容是选取合适的 NUMA 节点缓存,优先使用我们指定的 NUMA 节点,如果指定的 NUMA 节点中没有足够的内存,内核就会跨 NUMA 节点按照访问距离的远近,选取一个合适的 NUMA 节点。
然后通过 get_partial_node 在选取的 NUMA 节点缓存 kmem_cache_node->partial 链表中查找 slab。
/*
* Try to allocate a partial slab from a specific node.
*/
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
struct kmem_cache_cpu *c, gfp_t flags)
{
// 接下来就会挨个遍历 kmem_cache_node 的 partial 列表中的 slub
// 这两个变量用于临时存储遍历的 slub
struct page *page, *page2;
// 用于指向从 partial 列表 slub 中申请到的对象
void *object = NULL;
// 用于记录 slab cache 本地 cpu 缓存 kmem_cache_cpu 中所缓存的空闲对象总数(包括 partial 列表)
// 后续会向 kmem_cache_cpu 中填充 slub
unsigned int available = 0;
// 临时记录遍历到的 slub 中包含的剩余空闲对象个数
int objects;
spin_lock(&n->list_lock);
// 开始挨个遍历 kmem_cache_node 的 partial 列表,获取 slub 用于分配对象以及填充 kmem_cache_cpu
list_for_each_entry_safe(page, page2, &n->partial, slab_list) {
void *t;
// page 表示当前遍历到的 slub,这里会从该 slub 中获取空闲对象赋值给 t
// 并将 slub 从 kmem_cache_node 的 partial 列表上摘下
t = acq