uire_slab(s, n, page, object == NULL, &objects);
// 如果 t 是空的,说明 partial 列表上已经没有可供分配对象的 slub 了
// slub 都满了,退出循环,进入伙伴系统重新申请 slub
if (!t)
break;
// objects 表示当前 slub 中包含的剩余空闲对象个数
// available 用于统计目前遍历的 slub 中所有空闲对象个数
// 后面会根据 available 的值来判断是否继续填充 kmem_cache_cpu
available += objects;
if (!object) {
// 第一次循环会走到这里,第一次循环主要是满足当前对象分配的需求
// 将 partila 列表中第一个 slub 缓存进 kmem_cache_cpu 中
c->page = page;
stat(s, ALLOC_FROM_PARTIAL);
object = t;
} else {
// 第二次以及后面的循环就会走到这里,目的是从 kmem_cache_node 的 partial 列表中
// 摘下 slub,然后填充进 kmem_cache_cpu 的 partial 列表里
put_cpu_partial(s, page, 0);
stat(s, CPU_PARTIAL_NODE);
}
// 这里是用于判断是否继续填充 kmem_cache_cpu 中的 partial 列表
// kmem_cache_has_cpu_partial 用于判断 slab cache 是否配置了 cpu 缓存的 partial 列表
// 配置了 CONFIG_SLUB_CPU_PARTIAL 选项意味着开启 kmem_cache_cpu 中的 partial 列表,没有配置的话, cpu 缓存中就不会有 partial 列表
// kmem_cache_cpu 中缓存被填充之后的空闲对象个数(包括 partial 列表)不能超过 ( kmem_cache 结构中 cpu_partial 指定的个数 / 2 )
if (!kmem_cache_has_cpu_partial(s)
|| available > slub_cpu_partial(s) / 2)
// kmem_cache_cpu 已经填充满了,就退出循环,停止填充
break;
}
spin_unlock(&n->list_lock);
return object;
}
get_partial_node 函数通过遍历 NUMA 节点缓存结构 kmem_cache_node->partial 链表主要做两件事情:
-
将第一个遍历到的 slab 从 partial 链表中摘下,提升为本地 cpu 缓存 kmem_cache_cpu->page。
-
继续遍历 partial 链表,后面遍历到的 slab 会填充进本地 cpu 缓存 kmem_cache_cpu->partial 链表中,直到当前 cpu 缓存的所有空闲对象数目 available (既包括 kmem_cache_cpu->page 中的空闲对象也包括 kmem_cache_cpu->partial 链表中的空闲对象)超过了 kmem_cache->cpu_partial / 2 的限制。
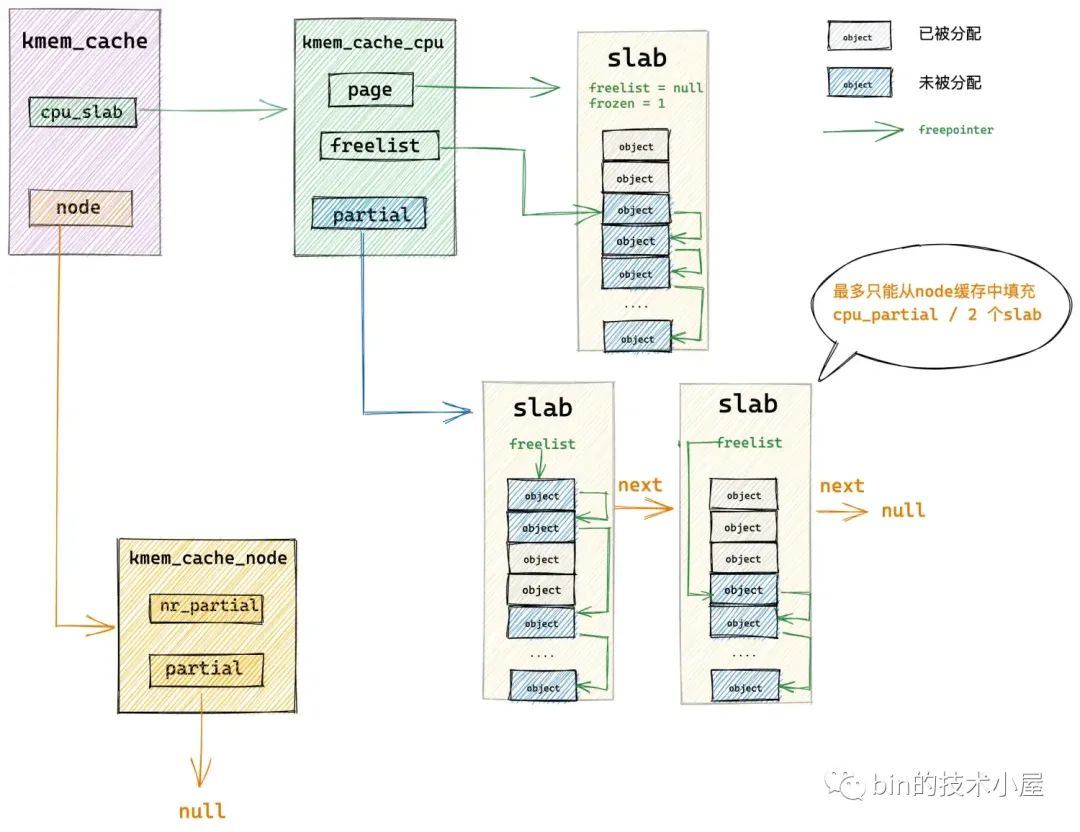
现在 slab cache 的本地 cpu 缓存已经被填充好了,随后内核会从 kmem_cache_cpu->freelist 中分配一个空闲对象出来给进程使用。
3.2.2 从 NUMA 节点缓存 partial 链表中将 slab 摘下
// 从 kmem_cache_node 的 partial 列表中摘下一个 slub 分配对象
// 随后将摘下的 slub 放入 cpu 本地缓存 kmem_cache_cpu 中缓存,后续分配对象直接就会 cpu 缓存中分配
static inline void *acquire_slab(struct kmem_cache *s,
struct kmem_cache_node *n, struct page *page,
int mode, int *objects)
{
void *freelist;
unsigned long counters;
struct page new;
lockdep_assert_held(&n->list_lock);
// page 表示即将从 kmem_cache_node 的 partial 列表摘下的 slub
// 获取 slub 中的空闲对象列表 freelist
freelist = page->freelist;
counters = page->counters;
new.counters = counters;
// objects 存放该 slub 中还剩多少空闲对象
*objects = new.objects - new.inuse;
// mode = true 表示将 slub 摘下之后填充到 kmem_cache_cpu 缓存中
// mode = false 表示将 slub 摘下之后填充到 kmem_cache_cpu 缓存的 partial 列表中
if (mode) {
new.inuse = page->objects;
new.freelist = NULL;
} else {
new.freelist = freelist;
}
// slub 放入 kmem_cache_cpu 之后需要冻结,其他 cpu 不能从这里分配对象,只能释放对象
new.frozen = 1;
// 更新 slub (page表示)中的 freelist 和 counters
if (!__cmpxchg_double_slab(s, page,
freelist, counters,
new.freelist, new.counters,
"acquire_slab"))
return NULL;
// 将 slub (page表示)从 kmem_cache_node 的 partial 列表上摘下
remove_partial(n, page);
// 返回 slub 中的空闲对象列表
return freelist;
}
3.3 从伙伴系统中重新申请 slab
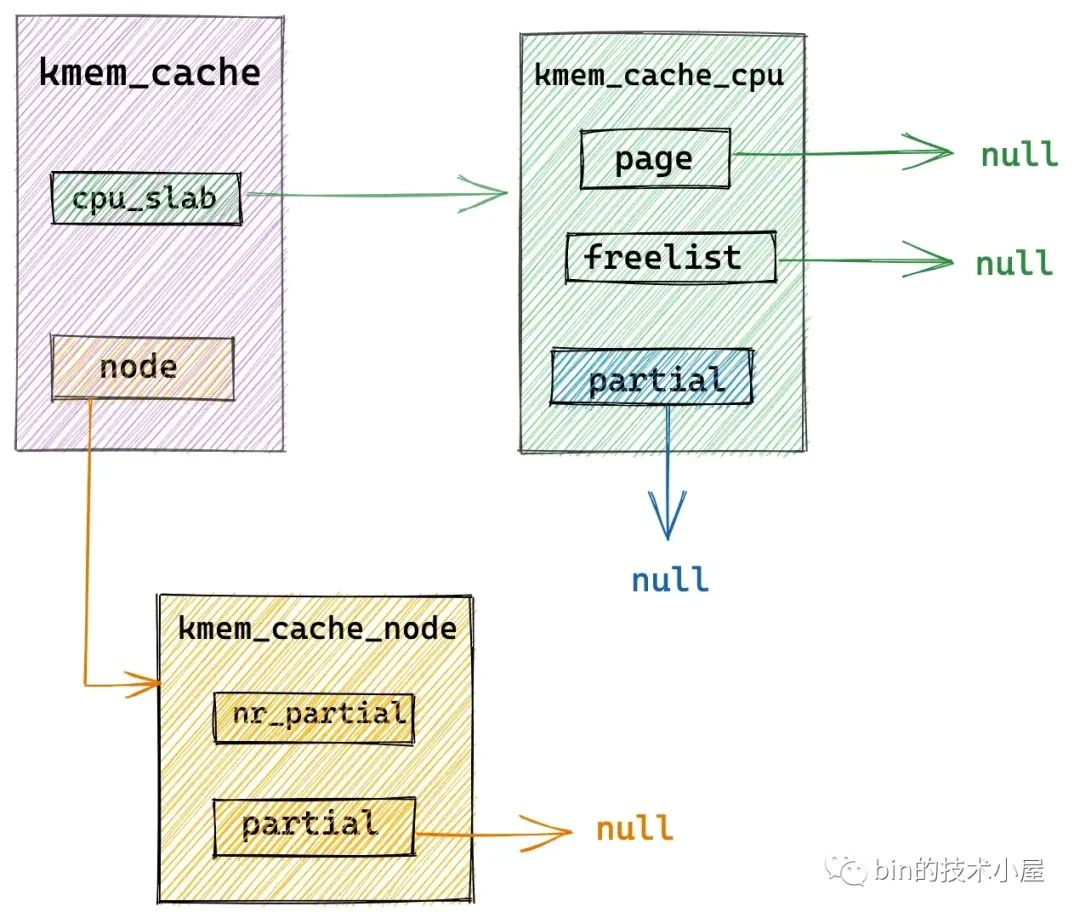
假设 slab cache 当前的架构如上图所示,本地 cpu 缓存 kmem_cache_cpu->page 为空,kmem_cache_cpu->partial 为空,kmem_cache_node->partial 链表也为空,比如 slab cache 在刚刚被创建出来的时候就是这个架构。
在这种情况下,内核就需要通过 new_slab 函数到伙伴系统中申请一个新的 slab,填充到 slab cache 的本地 cpu 缓存 kmem_cache_cpu->page 中。
static struct page *new_slab(struct kmem_cache *s, gfp_t flags, int node)
{
return allocate_slab(s,
flags & (GFP_RECLAIM_MASK | GFP_CONSTRAINT_MASK), node);
}
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
// 用于指向从伙伴系统中申请到的内存页
struct page *page;
// kmem_cache 结构的中的 kmem_cache_or