der_objects oo,表示该 slub 需要多少个内存页,以及能够容纳多少个对象
// kmem_cache_order_objects 的高 16 位表示需要的内存页个数,低 16 位表示能够容纳的对象个数
struct kmem_cache_order_objects oo = s->oo;
// 控制向伙伴系统申请内存的行为规范掩码
gfp_t alloc_gfp;
void *start, *p, *next;
int idx;
bool shuffle;
// 向伙伴系统申请 oo 中规定的内存页
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page)) {
// 如果伙伴系统无法满足正常情况下 oo 指定的内存页个数
// 那么这里再次尝试用 min 中指定的内存页个数向伙伴系统申请内存页
// min 表示当内存不足或者内存碎片的原因无法满足内存分配时,至少要保证容纳一个对象所使用内存页个数
oo = s->min;
alloc_gfp = flags;
// 再次向伙伴系统申请容纳一个对象所需要的内存页(降级)
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page))
// 如果内存还是不足,则走到 out 分支直接返回 null
goto out;
stat(s, ORDER_FALLBACK);
}
// 初始化 slub 对应的 struct page 结构中的属性
// 获取 slub 可以容纳的对象个数
page->objects = oo_objects(oo);
// 将 slub cache 与 page 结构关联
page->slab_cache = s;
// 将 PG_slab 标识设置到 struct page 的 flag 属性中
// 表示该内存页 page 被 slub 所管理
__SetPageSlab(page);
// 用 0xFC 填充 slub 中的内存,用于内核对内存访问越界检查
kasan_poison_slab(page);
// 获取内存页对应的虚拟内存地址
start = page_address(page);
// 在配置了 CONFIG_SLAB_FREELIST_RANDOM 选项的情况下
// 会在 slub 的空闲对象中以随机的顺序初始化 freelist 列表
// 返回值 shuffle = true 表示随机初始化 freelist,shuffle = false 表示按照正常的顺序初始化 freelist
shuffle = shuffle_freelist(s, page);
// shuffle = false 则按照正常的顺序来初始化 freelist
if (!shuffle) {
// 获取 slub 第一个空闲对象的真正起始地址
// slub 可能配置了 SLAB_RED_ZONE,这样会在 slub 对象内存空间两侧填充 red zone,防止内存访问越界
// 这里需要跳过 red zone 获取真正存放对象的内存地址
start = fixup_red_left(s, start);
// 填充对象的内存区域以及初始化空闲对象
start = setup_object(s, page, start);
// 用 slub 中的第一个空闲对象作为 freelist 的头结点,而不是随机的一个空闲对象
page->freelist = start;
// 从 slub 中的第一个空闲对象开始,按照正常的顺序通过对象的 freepointer 串联起 freelist
for (idx = 0, p = start; idx < page->objects - 1; idx++) {
// 获取下一个对象的内存地址
next = p + s->size;
// 填充下一个对象的内存区域以及初始化
next = setup_object(s, page, next);
// 通过 p 的 freepointer 指针指向 next,设置 p 的下一个空闲对象为 next
set_freepointer(s, p, next);
// 通过循环遍历,就把 slub 中的空闲对象按照正常顺序串联在 freelist 中了
p = next;
}
// freelist 中的尾结点的 freepointer 设置为 null
set_freepointer(s, p, NULL);
}
// slub 的初始状态 inuse 的值为所有空闲对象个数
page->inuse = page->objects;
// slub 被创建出来之后,需要放入 cpu 本地缓存 kmem_cache_cpu 中
page->frozen = 1;
out:
if (!page)
return NULL;
// 更新 page 所在 numa 节点在 slab cache 中的缓存 kmem_cache_node 结构中的相关计数
// kmem_cache_node 中包含的 slub 个数加 1,包含的总对象个数加 page->objects
inc_slabs_node(s, page_to_nid(page), page->objects);
return page;
}
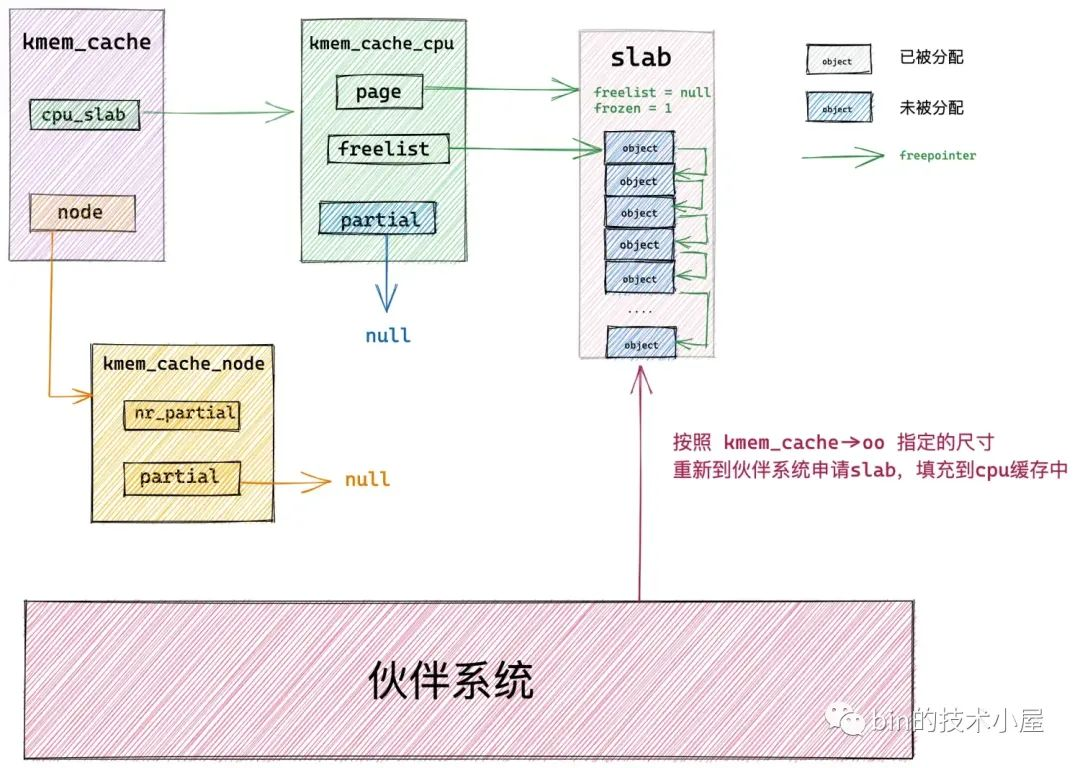
内核在向伙伴系统申请 slab 之前,需要知道一个 slab 具体需要多少个物理内存页,而这些信息定义在 struct kmem_cache 结构中的 oo 属性中:
struct kmem_cache {
// 其中低 16 位表示一个 slab 中所包含的对象总数,高 16 位表示一个 slab 所占有的内存页个数。
struct kmem_cache_order_objects oo;
}
通过 oo 的高 16 位获取 slab 需要的物理内存页数,然后调用 alloc_pages 或者 __alloc_pages_node 向伙伴系统申请。
static inline struct page *alloc_slab_page(struct kmem_cache *s,
gfp_t flags, int node, struct kmem_cache_order_objects oo)
{
struct page *page;
unsigned int order = oo_order(oo);
if (node == NUMA_NO_NODE)
page = alloc_pages(flags, order);
else
page = __alloc_pages_node(node, flags, order);
return page;
}
关于 alloc_pages 函数分配物理内存页的详细过程,感兴趣的读者可以回看下 《深入理解 Linux 物理内存分配全链路实现》
如果当前 NUMA 节点中的空闲内存不足,或者由于内存碎片的原因导致伙伴系统无法满足 slab 所需要的内存页个数,导致分配失败。
那么内核会降级采用 kmem_cache->min 指定的尺寸,向伙伴系统申请只容纳一个对象所需要的最小内存页个数。
struct kmem_cache {
// 当按照 oo 的尺寸为 slab 申请内存时,如果内存紧张,会采用 min 的尺寸为 slab 申请内存,可以容纳一个对象即可。
struct kmem_cache_order_objects min;
}
如果伙伴系统仍然无法满足,那么就只能跨 NUMA 节点分配了。如果成功地向伙伴系统申请到了 slab 所需要的内存页 page。紧接着就会初始化