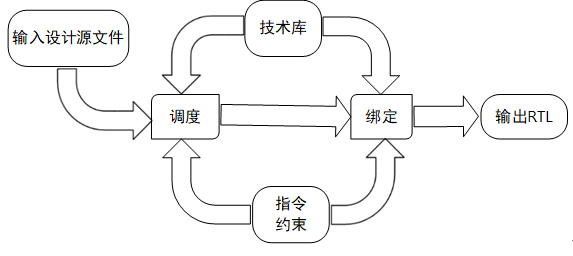
Ҫ�������ͨ��Լ����ָ�����Ż�RTLģ�͡�������Ż����̣���Ȼ��һ����Ʒ��������Ĺ��̡�
4���߲���ۺ������ղ�����RTL���������RTL�ļ���VHDL �� Verilog ���룩��Ҳ�����Ǵ���õ�IP�����Ա㱻������ƹ��߷���ĵ��á�
4. �߲���ۺ����ĺ��Ĺ���
�����������У��߲���ۺ�����ɵ�����Ҫ��Ҳ����ӵ��ǵ�2���������ɸ������ۺϲ���RTL����ģ�͵IJ��֡���������ֿ���ϸ��Ϊ����ȡ����ͨ·�Ϳ���ͨ·�����ȺͰ��Ż������Ρ����У�����ȡ����ͨ·�Ϳ���ͨ·����ָ���������Դ��룬��������Ĺ��ܡ�����ֽ�Ϊ������ͨ·�����ֵ�·�͡����ơ����ֵ�·�����Զ����������д��������㣬�Լ����ơ�Э���������ļ�����̡������ȺͰ���·Ҫ��ɵ�����Ϳ��ƹ������䵽��ͬ��ʱ�ӽ��ĺ�����Դ����ɡ����Ż�������ָͨ��ͼ8.1.3�е�Լ����ָ�������Ƹ߲���ۺ����ĵ��ȺͰ��Ӷ�ʵ�ַ����������Ľ��ۺϽ���Ĺ��̡�
1������ӳٺ����������
����ӳٺ��������Ǻ����߲���ۺ�������RTLģ������Ҫ������ָ��������ڽ��ܸ߲���ۺ����Ĺ���֮ǰ�Ƚ�Ҫ�������������
����ӳ٣�Latency����ָ������������Դ�������������£�ʵ���㷨����Ҫ��ʱ�ӽ�������


1 void foo(a,b,c,d,*x,*y){
2 ����
3 func_A(a, b, t1);
4 func_B(a, b, t2);
5 func_C(c, t1, &x);
6 func_D(d, t2, &y);
7 }
����8.1
ʹ�ø߲���ۺ���ʵ�ִ���8.1��ʾ���㷨���粻�����κ��Ż������õ���ͼ8.1.4��ʾ�ĵ�·����ʱ��ͼ��������ӳپ���10��ʱ�����ڡ�
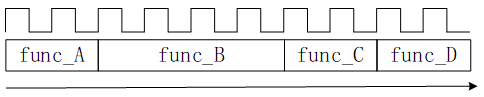
ͼ8.1.4 ����ӳپ���
�����������Throughput����ָ������������Դ�������������£����������루�������֮�����������ͼ8.1.4��������Ҳ������10��ʱ�����ڡ�
�Ķ����˶���һ���������ɻ�Ȼ����ӳٺ����������������ͬ��ΪʲôҪ��������ͬ���֣���ʵ����ͼ8.1.4�������ۡ����������ĺ���ʱ����δ���ǵ�·�����������������Ӳ����·������ʵ���㷨��һ�����ɱ�������ϲ�ͬ���ֵ�Ӳ����·����ͬʱִ�жಽ���㣬����CPUִ�и��������ֻ��һ������ִ�С��������ɱ�������е�һ���ֵ�·ִ��ͼ8.1.4��func_Bʱ��ԭ��ִ��func_A�ĵ�·�Ϳ����ٴ�ȡһ���µ�����ִ�У��Ӷ����������·������������ͼ8.1.5��ʾ����·�������������Ϊ4�����ڡ�
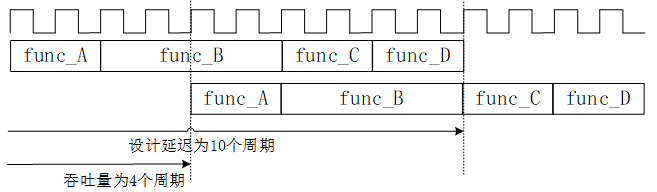
ͼ8.1.5 �������������
2�����ȺͰ�
������һ�ξ����C����������˵���߲���ۺ����������ͨ�������ȡ�����ͬ�����ݲ���ӳ�䵽��ͬ��ʱ�ӽ����еġ�����������ʾ�����б���t1��t2��t3��out֮�����������ϵ��ֻ�����μ���õ���һ��������ֵ�����ܵõ���һ��������ֵ��
void foo{
����
t1 = a * b;
t2 = c + t1;
t3 = d * t2;
out = t3 �C e;
}
����8.2
������Ҫ��̫���������㷨���ķѵ�ʱ�䣨����ӳ٣�������Բ�����ͼ8.1.6��ʾ�ĵ��Ȳ��ԡ�����һ��ʱ�ӽ���ʵ��a×b���ڶ���ʱ�ӽ���ʵ��ʵ��c+t1��������ʱ�ӽ���ʵ��ʵ��d×t2�����ĸ�ʱ�ӽ���ʵ��ʵ��t3�Ce���ܹ�����4��ʱ�ӵ�ʱ�䣬ÿ�����Ķ�Ӧ�ļ����������ô���������������õ��ȷ���������ʹ����������Դ�ӳٵ�Ҫ��Ҳ��͡�
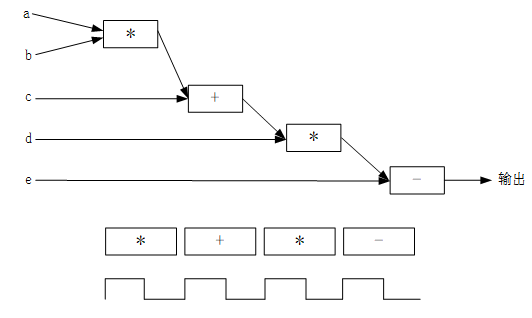
ͼ8.1.6 ���Ȳ���һʾ��ͼ
�������Ҫ�㷨���Ľ��ٵ�ʱ����ʵ�ָ��ߵ��������������ͨ��ȥ��ijЩ���津�����ķ����������������ϲ�������ʱ�ӽ���������ɡ���Ȼ���������Ĵ����������ĵ�������Դ�ܹ��ڸ��̵�ʱ������ɸ������������㡣ͼ8.1.7��ʾ���ǽ�a×b��c+t1��d×t2����ϲ���һ��ʱ�ӽ�������ɣ��Ӷ����ܺ�ʱ���͵�2��ʱ�ӽ��ĵĵ��Ȳ��ԡ�

ͼ8.1.7 ���Ȳ��Զ�ʾ��ͼ
������ָ�ѵ������漰�����㡰ָ�ɡ������������Դ��ʵ�֣���ʵ����Դ��ӳ�䣬���Կ��Դ��·�Ϊ�����ͷǹ������֡�����˼�壬��������ָ������㹲��ͬһ���ɱ��Ӳ����Դ����Ȼ������ǰ���Dz�ͬ���㲻����ͬһ��ʱ�ӽ�����ʹ�ø���Դ����ͼ8.1.7��ʾ�ĵ��Ȳ����У������˷����㶼�����䵽��һ��ʱ�ӽ�������ɣ�������ʱ�ӽ�����ʹ�õij˷�����Դ���Dz����Թ����ġ�
���ȺͰ���һ��������Ĺ��̣����ǹ�ͬ�����ڼ�����Ļ����ϣ����ܵ��û�ָ������ƣ�ʵ�ֺ����ĵ��ȺͰ�ע����һ�������Դ����Ż��Ĺ��̡�
ͼ8.1.8 ���ȺͰ���ʾ��ͼ
3����������ӳٺ�������
�߲���ۺ����ĺ��Ĺ������Ǿ���ͨ�����ȺͰ����������ռ����Դ/�����ʱ��Ƶ�ʺ�������Ҫ���ǰ���£������ѵ��ӳٺ�������������������ӳٺ���������˼·�����¡�
��һ����������֮��Ĺ����ԣ���������ӳ١�
�ٿ��Ǵ���8.1��ʾ���㷨��������ڴ�ͳ��CPU��ִ����Щ���룬��ֻ����ͼ8.1.4��ʾ��ʱ������ִ��func_A��func_B��func_C��func_D������ӳ�Ϊ10��ʱ�����ڡ������Ǹ�������ģ��֮���������ϵ�ǣ�ֻ�����func_A���ܵõ�t1������ִ��func_C��ֻ�����func_B���ܵõ�t2����ִ��func_D����func_A/func_C��func_B/func_D֮�䲢û����Լ��ϵ����ͼ8.1.9��ʾ��
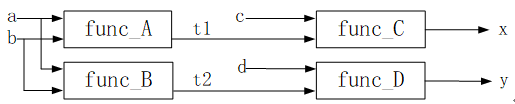
ͼ8.1.9 ����������ϵ�ĵ���
���߿���ͨ�����Լ���������Ż����ȺͰ�ʽ������Ƶ�����ͨ·����Ϊͼ8.1.10��ʾ����������������ӳٽ���Ϊ6����
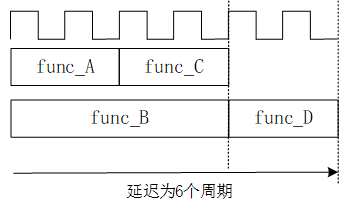
ͼ8.1.10 ����ӳ��Ż�ʾ��ͼ
�����������������ϵ�����������£���������Ӳ����Դ�Ĺ���ʱ�����̶ȵ���߸���ģ��IJ��жȡ�ʹ��ɲ�ͬ���ܵ�Ӳ����Դ����ˮ�ߡ��ϵĹ���һ������ij��������������Ա��������������еľ������ݷֱ���С��ӹ����������Ӷ�����������������ͬ���������C����α����Ϊ����������ͼ8.1.10��ʾ���ӳ��Ż����ĸ�����˳��ִ�У�������func_A��func_B��func_C��func_D�൱����ˮ��������ض����ܵġ����ˡ��������Ͻ�����������൱����Ҫ�ӹ��ġ�������������func_A��func_B��func_C��func_D������ӳٷֱ�Ϊ2��4��2��2��ʱ�����ڣ����ͨ�����Ƚ��ظ�ִ�е�����ͨ·���л�����ͼ8.1.11��ʾ��ÿ������ͨ·���л�����ӳ٣�Ϊ�ĸ�������ִ��ʱ�����4��ʱ�����ڡ�������������������ͨ������ͨ·��·�������ӳ���Ȼ��Ϊ10��ʱ�����ڣ�������������Ϊ3��ʱ�����ڡ�

ͼ8.1.11 ����������Ż�ʾ��ͼ
[ԭ��www.cnblogs.com/helesheng]