ointers(keytype) {
otyp = types.Types[TUINTPTR]
}
overflow := makefield("overflow", otyp)
field = append(field, overflow)
// ...
t.MapType().Bucket = bucket
bucket.StructType().Map = t
return bucket
}
这种做法是因为 Go 语言在执行哈希的操作时会直接操作内存空间,与此同时由于键值类型的不同占用的空间大小也不同,也就导致了类型和占用的内存不确定,所以没有办法在 Go 语言的源代码中进行声明。
我们可以根据上面这个函数的实现对结构体 bmap 进行重建:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
每一个哈希表中的桶最多只能存储 8 个元素,如果桶中存储的元素超过 8 个,那么这个哈希表的执行效率一定会急剧下降,不过在实际使用中如果一个哈希表存储的数据逐渐增多,我们会对哈希表进行扩容或者使用额外的桶存储溢出的数据,不会让单个桶中的数据超过 8 个:
溢出桶只是临时的解决方案,创建过多的溢出桶最终也会导致哈希的扩容。
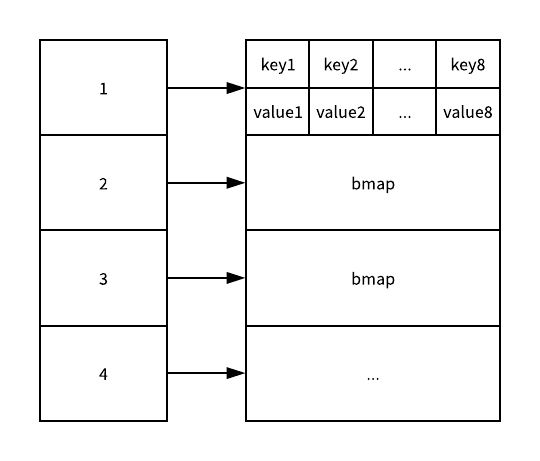
Go 语言的运行时会为哈希表分配内存空间,用于存储哈希表中的键值对,无论是哈希的结构还是桶的结构都是在运行时初始化的,只是后者并在源代码中存在事实的结构,它是一个使用代码生成的『虚拟』结构体。
操作
哈希表作为一种数据结构,我们肯定需要研究它的操作,也就是不同读写操作的实现原理,当我们谈到哈希表的读时,一般都是通过下标和遍历两种方式读取数据结构中存储的数据:
_ = hash[key]
for k, v := range hash {
// k, v
}
这两种方式虽然都是读取哈希表中的数据,但是使用的函数和底层的原理完全不同,前者需要知道哈希的键并且只能一个键对应的值,而后者可以遍历哈希中的全部键值对,访问数据时也不需要预先知道相应的键,我们会在后面的章节中介绍 range 的实现原理。
数据结构的写一般指的都是增加、删除和修改,增加和修改字段都是通过索引和赋值进行的,而删除字典中的数据需要使用关键字 delete:
hash[key] = value
hash[key] = newValue
delete(hash, key)
我们会对这些不同的操作一一讨论并给出它们底层具体的实现原理,这些操作大多都是通过编译期间和运行时共同实现的,介绍的过程中可能会省略一些编译期间的相关知识,具体的可以阅读之前的章节 编译过程概述 了解编译的过程和原理。
访问
在编译的 类型检查 阶段,所有的类似 hash[key] 的 OINDEX 操作都会被转换成 OINDEXMAP 操作,然后在 中间代码生成 之前会在 walkexpr 中将这些 OINDEXMAP 操作转换成如下的代码:
v := hash[key] // => v := *mapaccess1(maptype, hash, &key)
v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key)
赋值语句左侧接受参数的个数也会影响最终调用的运行时参数,当接受参数仅为一个时,会使用 mapaccess1 函数,同时接受键对应的值以及一个指示键是否存在的布尔值时就会使用 mapaccess2 函数,mapaccess1 函数仅会返回一个指向目标值的指针:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue() {
v = *((*unsafe.Pointer)(v))
}
return v
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
在这个函数中我们首先会通过哈希表设置的哈希函数、种子获取当前键对应的哈希,再通过 bucketMask 和 add函数拿到该键值对所在的桶和哈希最上面的 8 位数字,这 8 位数字最终就会与桶中存储的 tophash 作对比,每一个桶其实都存储了 8 个 tophash,就是编译期间的 topbits 字段,每一次都会与桶中全部的 8 个 uint8 进行比较,这 8 位的 tophash 其实就像是一级缓存,它存储的是哈希最高的 8 位,而选择桶时使用了桶掩码使用的是最低的几位,这种方式能够帮助我们快速判断当前的键值对是否存在并且减少碰撞:
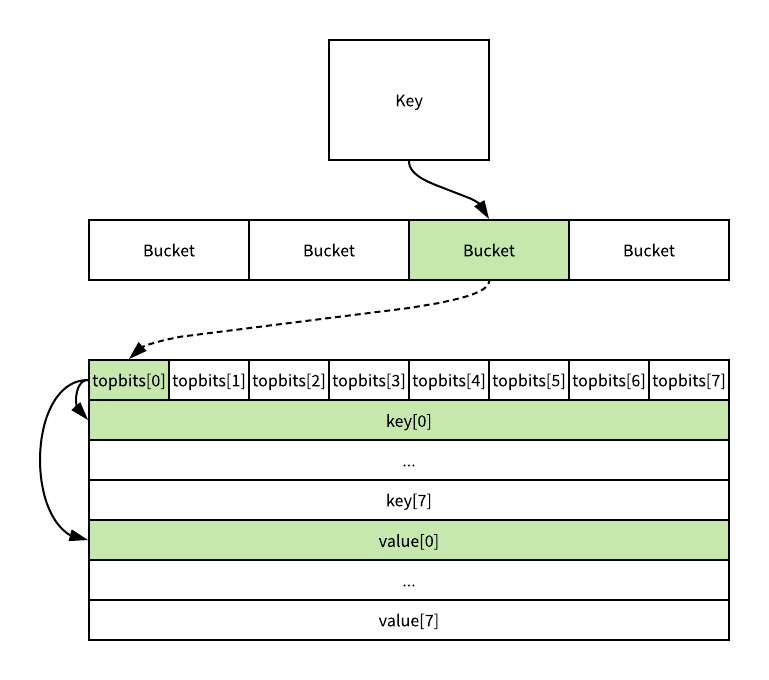
每一个桶都是一整片的内存空间,当我们发现某一个 topbits 与传入键的 tophash 匹配时,通过指针和偏移量获取哈希中存储的键并对两者进行比较,如果相同就会通过相同的方法获取目标值的指针并返回。
另一个同样用于访问哈希表中数据的 mapaccess2 函数其实只是在 mapaccess1 的基础上同时返回了一个标识当前数据是否存在的布尔值:
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
// ...
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// ...
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
/