1), color = "cyan") +
geom_line(aes(y = pred_test50), color = "red") +
geom_line(aes(y = pred_test100), color = "green") +
geom_line(aes(y = pred_test150), color = "violet") +
geom_line(aes(y = pred_test200), color = "cyan") +
geom_line(aes(y = pred_test250), color = "red") +
geom_line(aes(y = pred_test300), color = "green") +
geom_line(aes(y = pred_test350), color = "cyan") +
geom_line(aes(y = pred_test400), color = "red") +
geom_line(aes(y = pred_test450), color = "green") +
geom_line(aes(y = pred_test500), color = "cyan") +
geom_line(aes(y = pred_test550), color = "violet") +
ggtitle("Predictions on test set")
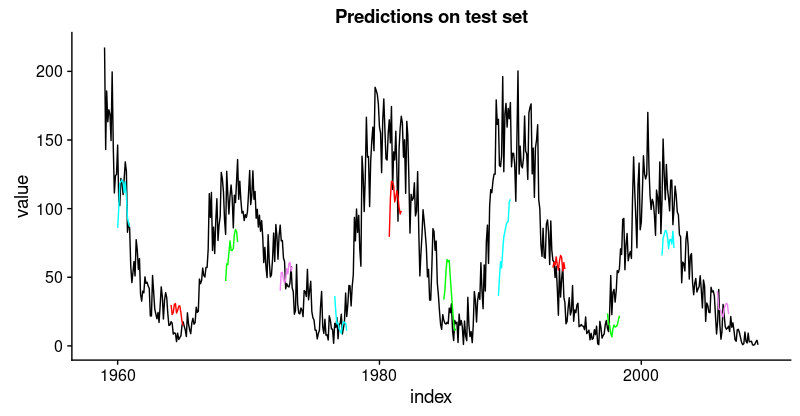
这不如训练集那么好,但也不错,因为这个时间序列非常具有挑战性。
在手动选择的示例分割中定义并运行我们的模型后,让我们现在回到我们的整体重新抽样框架。
在所有分割上回测模型
为了获得所有分割的预测,我们将上面的代码移动到一个函数中并将其应用于所有分割。它返回包含两个数据框的列表,分别对应训练和测试集,每个数据框包含模型的预测以及实际值。
obtain_predictions <- function(split)
{
df_trn <- analysis(split)[1:800, , drop = FALSE]
df_val <- analysis(split)[801:1200, , drop = FALSE]
df_tst <- assessment(split)
df <- bind_rows(
df_trn %>% add_column(key = "training"),
df_val %>% add_column(key = "validation"),
df_tst %>% add_column(key = "testing")) %>%
as_tbl_time(index = index)
rec_obj <- recipe(
value ~ ., df) %>%
step_sqrt(value) %>%
step_center(value) %>%
step_scale(value) %>%
prep()
df_processed_tbl <- bake(rec_obj, df)
center_history <- rec_obj$steps[[2]]$means["value"]
scale_history <- rec_obj$steps[[3]]$sds["value"]
FLAGS <- flags(
flag_boolean("stateful", FALSE),
flag_boolean("stack_layers", FALSE),
flag_integer("batch_size", 10),
flag_integer("n_timesteps", 12),
flag_integer("n_epochs", 100),
flag_numeric("dropout", 0.2),
flag_numeric("recurrent_dropout", 0.2),
flag_string("loss", "logcosh"),
flag_string("optimizer_type", "sgd"),
flag_integer("n_units", 128),
flag_numeric("lr", 0.003),
flag_numeric("momentum", 0.9),
flag_integer("patience", 10))
n_predictions <- FLAGS$n_timesteps
n_features <- 1
optimizer <- switch(
FLAGS$optimizer_type,
sgd = optimizer_sgd(
lr = FLAGS$lr, momentum = FLAGS$momentum))
callbacks <- list(
callback_early_stopping(patience = FLAGS$patience))
train_vals <- df_processed_tbl %>%
filter(key == "training") %>%
select(value) %>%
pull()
valid_vals <- df_processed_tbl %>%
filter(key == "validation") %>%
select(value) %>%
pull()
test_vals <- df_processed_tbl %>%
filter(key == "testing") %>%
select(value) %>%
pull()
train_matrix <- build_matrix(
train_vals, FLAGS$n_timesteps + n_predictions)
valid_matrix <- build_matrix(
valid_vals, FLAGS$n_timesteps + n_predictions)
test_matrix <- build_matrix(
test_vals, FLAGS$n_timesteps + n_predictions)
X_train <- train_matrix[, 1:FLAGS$n_timesteps]
y_train <- train_matrix[, (FLAGS$n_timesteps + 1):(FLAGS$n_timesteps * 2)]
X_train <- X_train[1:(nrow(X_train) %/% FL