目标反射回波检测算法及其FPGA实现之二:
互相关/卷积/FIR电路的实现
前段时间,接触了一个声呐目标反射回波检测的项目。声呐接收机要实现的核心功能是在含有大量噪声的反射回波中,识别出发射机发出的激励信号的回波。我会分几篇文章分享这个基于FPGA的回波识别算法的开发过程和原码,欢迎大家不吝赐教。以下原创内容欢迎网友转载,但请注明出处: https://www.cnblogs.com/helesheng。
在本系列博文的第一篇中,根据仿真结果,我认为采用“反射回波和激励信号互相关”来计算目标距离的算法具有较高性能和计算效率。作为系列文章的第二篇,本文将介绍算法的核心功能――互相关的FPGA实现方法。本文会以数据结构的实现方式为主线,综合考虑电路的计算实时性、灵活性和成本效率等方面问题。
要实现的互相关运算在连续域的描述方式为:
![]() (1)
(1)
其中M(t)为激励信号,s(t)为反射回波信号。在FPGA中实现上式时必须将其离散化,并限制在有限的时间长度内。好在激励信号M(t)本来就是有限时长的,对其实施一个满足奈奎斯特采样定理的离散化后【注:作为算法的验证,我们在预备篇中使用了采样率仅为50KSPS的ADC:MCP3202,但这并不妨碍我们验证算法的正确性。实际的声呐系统中采样率可能远超过50KSPS】,可以将上式简化为FPGA能够实现的形式:
![]()
其中N为激励信号的长度(采样点数)。
一望便知,上式是数字信号处理的典型计算――乘加(MAC)运算的组合。将激励信号M[t]镜像翻转:
![]()
就可以将(2)式变为我们熟悉的卷积算法:
![]()
当上式中的h[k[视为系统的冲击响应时,上式还可以理解为更为常见的FIR滤波算法。
由于激励信号一般具有镜像对称性(或称左右对称),即(3)式中翻转前的M[k]和h[k]和完全相同。为了使设计的FPGA电路具有更好的通用性,接下来不妨直接讨论卷积/FIR滤波运算(4)式的实现方式。
一、总体电路结构
中高端FPGA一般集成了硬件MAC电路,如Xilinx公司的DSP48E模块和Altera(Intel)公司的Embedded multipliers模块。这些MAC模块不需要占用FPGA中的通用可编程资源,工作频率可高达大几百MHz,且大大降低开发难度。但声呐系统的采样率一般不会超过10MHz,为了使本算法能够在高、中、低档的各类FPGA上兼容,我选择通过EDA工具提供的MAC的IP核实现算法。验证算法使用的是,不具备硬件MAC模块的,常见低成本FPGA:Cyclone-I系列。
为保证算法的实时性,必须在一个A/D采样周期内实现(4)式中的N个点的乘加运算。最直接的方式是在FPGA中实现N个乘加器,全并行的完成(4)式的计算。但这样做将耗费大量的FPGA资源(Cyclone-I中,每个16*16bits的乘加器约需500个LE资源),且当N确定后电路结构就固定了,不太容易修改。为使设计的电路更具“通用性”和“灵活性”,以兼容更多的激励信号长度N值,我才用下图所示的“半并行”结构实现(4)式的卷积算法。
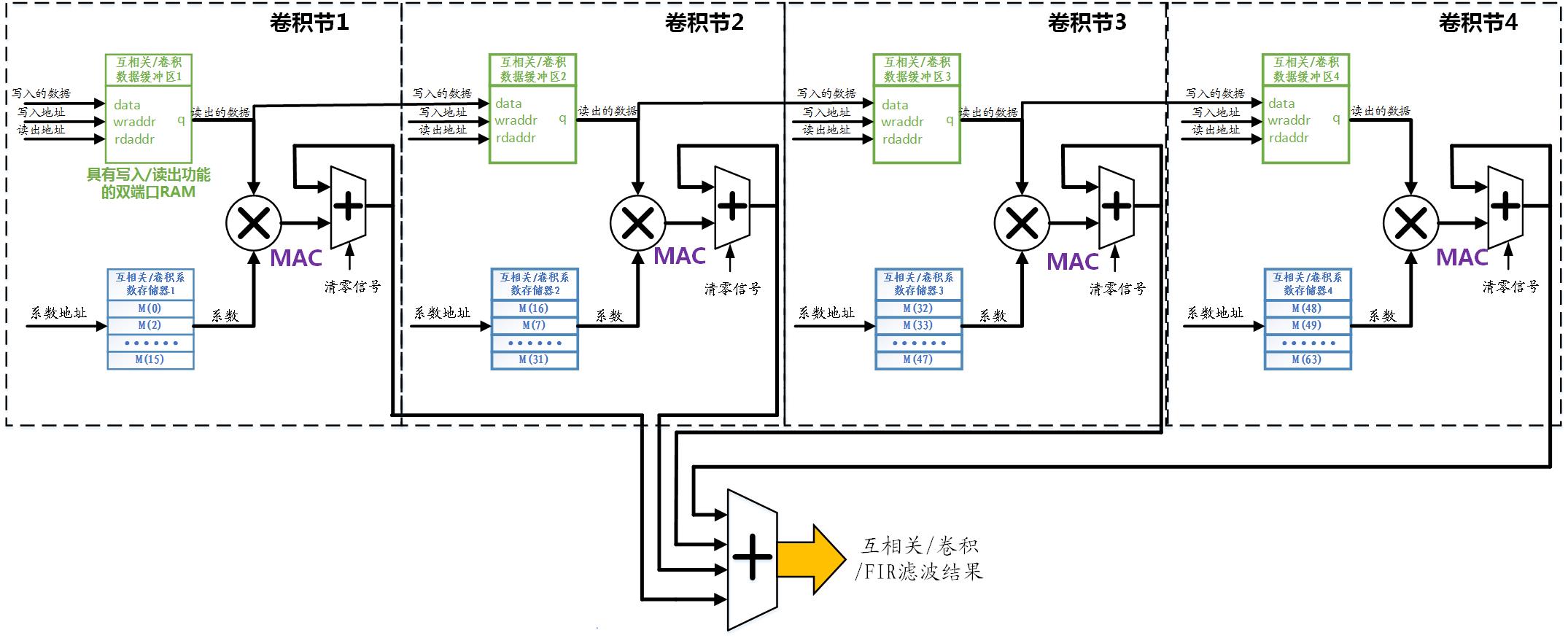
图1 半并行结构的互相关/卷积/FIR滤波器结构
这相当于将一段长度为N公里的“公路工程”,平均分配给L个“工程队”来实施。在每个工程队同时工作,且效率相同的前提下,工程耗时将降低为原来的1/L;当然L个工程队所需的“工资”也变为原来的L倍。实际使用时,可以根据总工程量N和FPGA的资源情况,灵活的调整L,从而在实时性和电路规模之间取得平衡。以下为方便讨论,且不失一般性,将以N=64,L=4为例讨论。
设计时虽然可以利用Verilog-HDL的泛化能力,将相同的功能模块例化为4个结构相同的“工程队”,以下简称为“卷积节”。在设计功能模块时,必须考虑输入数据s[k]和卷积模板h[k]存储的数据结构。必须满足以下要求:
1、在单个R[n]的计算中,每个卷积节需要遍历数据缓冲区中的所有s[k[数据,以及系数存储器中的所有卷积系数h[k]。
2、在完成一个R[n]的计算后,每个卷积节需要接收前一个卷积节或A/D采样得到的新缓冲数据,同时将缓冲中“最老”的数据传递给下一个卷积节。
我设计了图1所示“双存储器”结构实现上述两条数据结构功能,其物理载体都是Cyclone系列中的M4K存储块(M4K RAM blocks)。图中绿色部分是存储输入数据s[k]的缓冲区,是“简单双端口RAM”。它有两个数据端口:一个负责向缓冲区存入新数据,每个A/D采样周期存入一次;另一个负责读取乘加运算所需的数据,每个A/D采样周期读取16次(即N/L次)。其存取采用“环形队列”数据结构。图中蓝色部分是卷积系数h[k]的存储器,它每个A/D采样周期读取16次,数据不更新。
另外,当互相关/卷积的模板具备对称性时,也就是对应的FIR滤波器具有线性相位的情况下,图1所示的算法电路还能进一步简化,计算量降低为N/2次乘加MAC运算,这里就不讨论了。
二、卷积节控制电路的设计
通过上文的描述,相信读者可以感觉得到:整个卷积电路的重点在每个卷积节的实现,而卷积节实现的关键是能够正确的控制“数据缓冲区”、“系数存储器”和“乘加器(MAC)”的协调工作。其工作内容是在每个A/D采样结果到来,而下一个结果未到之前,完成:
1、产生一个写地址,将A/D结果存入缓冲区最老数据所在位置,同时将最老的数据输出给下一个卷积节;
2、同步产生两组、各16个读地址,分别从数据缓冲区和系数存储器读取一遍其中的所有数据;
3、将顺序读取的两组数据顺序乘加在一起。
实现上述功能的电路Verilog-HDL实现如下:


1 module conv_ctlr(rst_n,clk,start,coe_rom_addr,rd_data_dpram_addr,acc_clr,wren,wr_data_dpram_addr,flag,mac_en); 2 //卷积控制信号产生电路模块 3 //可以控制一个MAC电路,分多个时钟周期,实现多个数值的相加。 4 //这里实现的是控制16级卷积的功能 5 input rst_n;//低电平复位信号,可以复位首地址指针 6 input clk;//工作时钟信号 7 input start;//启动一次控制逻辑输出的