本文源码部分基于内核 5.4 版本讨论
在经过上篇文章 《从内核源码看 slab 内存池的创建初始化流程》 的介绍之后,我们最终得到下面这幅 slab cache 的完整架构图:
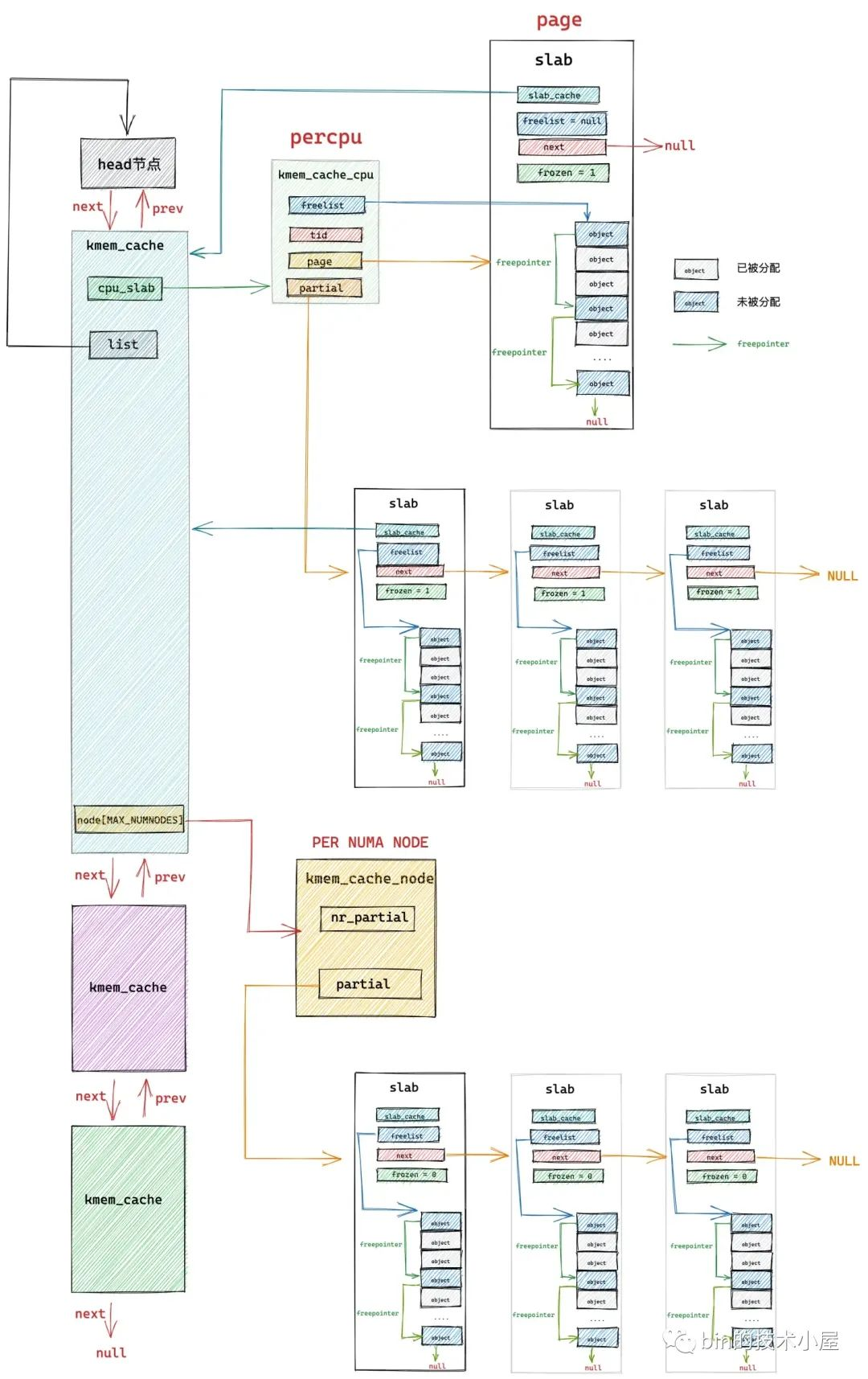
本文笔者将带大家继续从内核源码的角度继续拆解 slab cache 的实现细节,接下来笔者会基于上面这幅 slab cache 完整架构图,详细介绍一下 slab cache 是如何进行内存分配的。
1. slab cache 如何分配内存
当我们使用 fork() 系统调用创建进程的时候,内核需要为进程创建 task_struct 结构,struct task_struct 是内核中的核心数据结构,当然也会有专属的 slab cache 来进行管理,task_struct 专属的 slab cache 为 task_struct_cachep。
下面笔者就以内核从 task_struct_cachep 中申请 task_struct 对象为例,为大家剖析 slab cache 分配内存的整个源码实现。
内核通过定义在文件 /kernel/fork.c 中的 dup_task_struct 函数来为进程申请
task_struct 结构并初始化。
static struct task_struct *dup_task_struct(struct task_struct *orig, int node)
{
...........
struct task_struct *tsk;
// 从 task_struct 对象专属的 slab cache 中申请 task_struct 对象
tsk = alloc_task_struct_node(node);
...........
}
// task_struct 对象专属的 slab cache
static struct kmem_cache *task_struct_cachep;
static inline struct task_struct *alloc_task_struct_node(int node)
{
// 利用 task_struct_cachep 动态分配 task_struct 对象
return kmem_cache_alloc_node(task_struct_cachep, GFP_KERNEL, node);
}
内核中通过 kmem_cache_alloc_node 函数要求 slab cache 从指定的 NUMA 节点中分配对象。
// 定义在文件:/mm/slub.c
void *kmem_cache_alloc_node(struct kmem_cache *s, gfp_t gfpflags, int node)
{
void *ret = slab_alloc_node(s, gfpflags, node, _RET_IP_);
return ret;
}
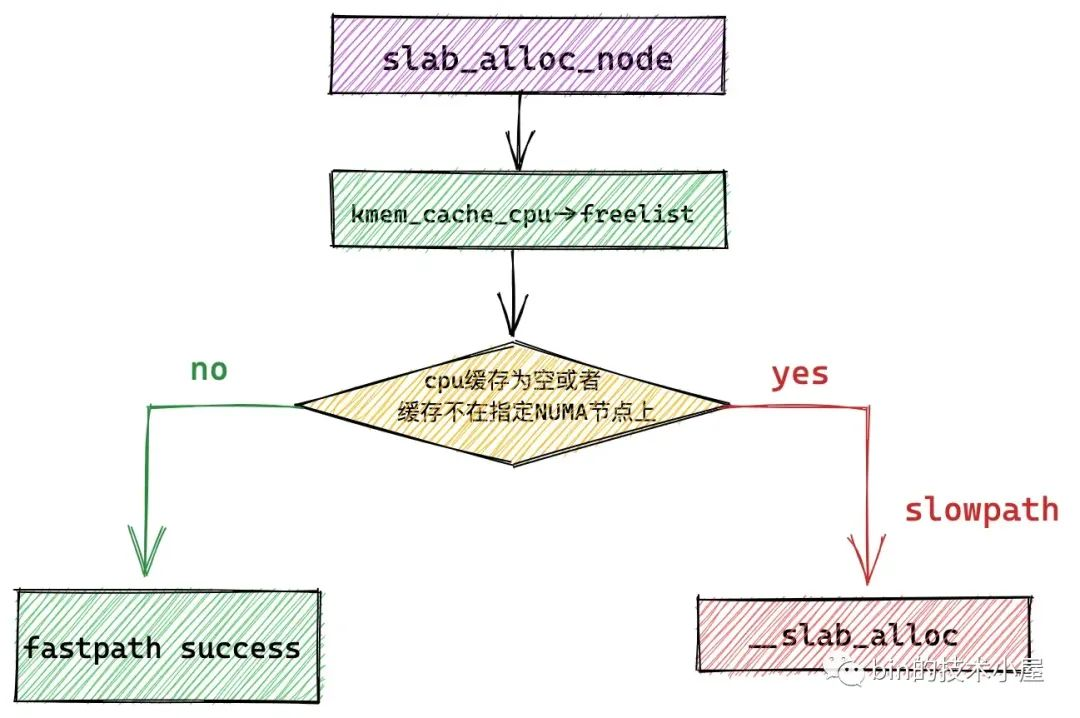
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
// 用于指向分配成功的对象
void *object;
// slab cache 在当前 cpu 下的本地 cpu 缓存
struct kmem_cache_cpu *c;
// object 所在的内存页
struct page *page;
// 当前 cpu 编号
unsigned long tid;
redo:
// slab cache 首先尝试从当前 cpu 本地缓存 kmem_cache_cpu 中获取空闲对象
// 这里的 do..while 循环是要保证获取到的 cpu 本地缓存 c 是属于执行进程的当前 cpu
// 因为进程可能由于抢占或者中断的原因被调度到其他 cpu 上执行,所需需要确保两者的 tid 是否一致
do {
// 获取执行当前进程的 cpu 中的 tid 字段
tid = this_cpu_read(s->cpu_slab->tid);
// 获取 cpu 本地缓存 cpu_slab
c = raw_cpu_ptr(s->cpu_slab);
// 如果开启了 CONFIG_PREEMPT 表示允许优先级更高的进程抢占当前 cpu
// 如果发生抢占,当前进程可能被重新调度到其他 cpu 上运行,所以需要检查此时运行当前进程的 cpu tid 是否与刚才获取的 cpu 本地缓存一致
// 如果两者的 tid 字段不一致,说明进程已经被调度到其他 cpu 上了, 需要再次获取正确的 cpu 本地缓存
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
// 从 slab cache 的 cpu 本地缓存 kmem_cache_cpu 中获取缓存的 slub 空闲对象列表
// 这里的 freelist 指向本地 cpu 缓存的 slub 中第一个空闲对象
object = c->freelist;
// 获取本地 cpu 缓存的 slub,这里用 page 表示,如果是复合页,这里指向复合页的首页 head page
page = c->page;
if (unlikely(!object || !node_match(page, node))) {
// 如果 slab cache 的 cpu 本地缓存中已经没有空闲对象了
// 或者 cpu 本地缓存中的 slub 并不属于我们指定的 NUMA 节点
// 那么我们就需要进入慢速路径中分配对象:
// 1. 检查 kmem_cache_cpu 的 partial 列表中是否有空闲的 slub
// 2. 检查 kmem_cache_node 的 partial 列表中是否有空闲的 slub
// 3. 如果都没有,则只能重新到伙伴系统中去申请内存页
object = __slab_alloc(s, gfpflags, node, addr, c);
// 统计 slab cache 的状态信息,记录本次分配走的是慢速路径 slow path
stat(s, ALLOC_SLOWPATH);
} else {
// 走到该分支表示,slab cache 的 cpu 本地缓存中还有空闲对象,直接分配
// 快速路径 fast path 下分配成功,从当前空闲对象中获取下一个空闲对象指针 next_object
void *next_object = get_freepointer_safe(s, object);
// 更新 kmem_cache_cpu 结构中的 freelist 指向 next_object
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))) {
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
// cpu 预取 next_object 的 freepointer 到 cpu 高速缓存,加快下一次分配对象的速度
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH);
}
// 如果 gfpflags 掩码中设置了 __GFP_ZERO,则需要将对象所占的内存初始化为零值
if (unlikely(slab_want