寻找集群,没有的话就自己创建一个,然后后续的其他节点也会加入这个节点,从而自动实现了自动集群化部署。
分片的管理
之前讲了一些分片的知识,但并没有具体用到,可能有些人已经忘了这个概念。这里重新讲一下。
梳理
文档的数据是存储到索引中的,而索引的数据是存储在分片上的,而分片是位于节点上的。
分片shard有主分片primary shard和复制分片replica shard两种,其中主分片是主要存储的分片,可以进行读写操作;副本分片是主分片的备份,可以进行读操作(不支持写操作)。
查询可以在主分片或副本分片上进行查询,这样可以提供查询效率。【但数据的修改只发生在主分片上。】
分片是面向索引的,分片上的数据属于同一个索引,在我们创建索引的时候,可以指定主分片和副本分片的数量,默认是5个主分片,5个副本分片。
索引的replica shard的数量可以修改,但primary shard的数量不可以修改。【一个Primary Shard可以有多个Replica Shard,默认创建是1个。】
修改replica shard数量:
PUT /douban/_settings
{
"number_of_replicas":1
}
为了保证数据的不丢失,通常来说Replica Shard不能与其对应的Primary Shard处于同一个节点中。【因为万一这个节点损坏了,那么存储在这个节点上的原数据(primary shard)和备份数据(replica shard)就全部丢失了】,但是可以和其他primary shard的replica shard放在一起
replica shard是primary shard的副本分片,负责承载一定的读请求,当primary shard都挂掉后,其中一个replica shard会变成primary shard来维持写功能。
分片的均衡分配
分片是分配到节点上的,但它会默认地均衡分配。
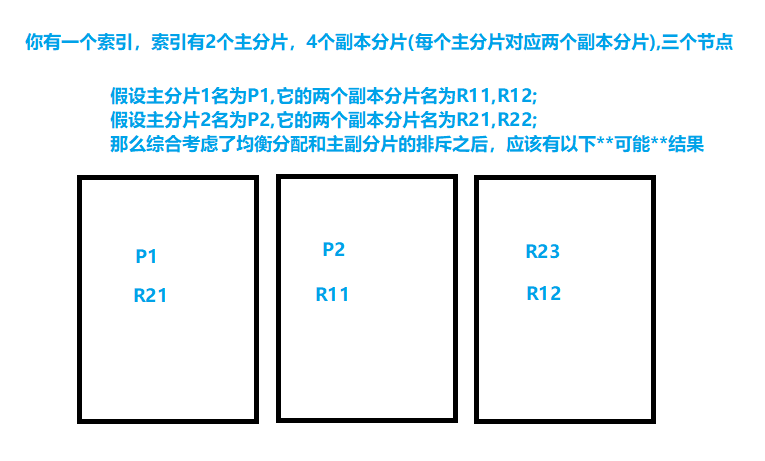
所谓均衡分配,以情况举例:【priX代表主分片XX,repX代表副本分片XX】
1.索引有1个priA,1个repA,但当前只有一个节点A,那么priA分配到A节点;repA没有分配。优先分配主分片。
2.索引有1个priA,1个repA,当前有两个节点A和B,那么priA分配到A节点;repA分配到B节点(priA分配到B节点也有可能)。
3.索引当前有2个priA,4个repA,有3个节点,那么现在每台节点上有两个分片(但要考虑主分片不能与自己的副本分片同在一个节点上,在下面的“ 主副分片的排斥”中由一个例子)。
【当后续新增节点的时候,会自动再次重新均衡分配。】
主副分片的排斥
考虑到备份的安全性,不应该让主分片和副本分片位于一个节点上,不然可能完全丢失数据。(比如你为了避免丢失钥匙,你给你家的门准备两条钥匙,你有一个钱包和一个背包,结果你把两条钥匙都放到钱包中,某天你钱包丢了,于是你回不了家了。。。所以你应该把钥匙分开放。)
对应的排斥情况就是:
1.索引有1个priA,1个repA,但当前只有一个节点A,那么priA分配到A节点;repA没有分配。
2.索引有1个priA,1个repA,当前有两个节点A和B,那么priA分配到A节点;repA分配到B节点(priA分配到B节点也有可能)。
【请注意,主分片与副本分片不能在一起,但副本分片和副本分片能存放在一起】
在上面的“分片的均衡分配”没有提到主副分片的排斥的问题,下面再举一个例子【下述的分配结果还有可能是其他的】:
容错性:
既然提到了备份的安全性,那么就不得不提一下容错性了。节点是有可能宕机的,宕机后,那么这个节点的数据起码会暂时性的丢失,那么对于不同情况下,最多可以宕机多少个节点呢?下面举例:【pri = x代表主分片数量为X,rep是副本分片】
1.如果你只有一个节点,那么容错性为0,你不能宕机,宕机不完全意味着数据完全丢失,但暂停服务还是有的。
2.如果你有两个节点,pri = 2,rep = 2,那么此时分片分配应该是[P1R2, P2R1],此时容错性为一个,因为某个节点上有完整的两个分片的数据【此处一提,假设丢失了P2R1,那么R1R2中的R2会升级成primary shard来保持写功能】
3.后面的自己尝试算一下吧!要综合均衡分片和排斥性来考虑。
数据路由
每一个document会存储到唯一的一个primary shared和其副本分片replica shard 中,我们是怎么根据ID来知道这个document存储在哪个分片的呢?
ElasticSearch会自动根据document的id值来进行计算,最终得出一个小于分片数量的数值,这个数值就是分片在ElasticSearch中的序号,最终得出应该存储到哪个分片上。
类似原理举例,假设我现在有4个主分片,那么我给它们标序号0,1,2,3。现在进来一个ID为15的数据,我经过一系列计算之后,15入参之后假设得到243这个数值,然后我们使用243来对4求余,余数是3,所以就把这个数据放在序号为3的分片上。
依据这个原理,存储数据的时候就知道把数据放在哪个分片上;读取数据的时候也知道从哪个分片上读取数据。
【稍微提一下,在ElasticSearch全文搜索完成之后,此时内部得到的是ID组成的数组,内部再会根据ID来查找数据】
对于集群健康状态的影响
上面说了,集群状态受当前的primary shared和replica shared的数量影响。
小节总结:
本节重新讲了主分片和副本分片的功能,主分片和副本分片都有存储数据的功能,一个索引的数据平分到多个主分片上,副本分片拷贝对应主分片的数据;然后讲了ElasticSearch对于分片的自动均衡分配,和主分片和副本分片不能存储在一起的问题。然后讲了ElasticSearch如何根据ID来判断数据存储在哪个分片上。最后讲了节点上分片的分配对于集群健康状态的影响。
请求的处理
提供服务
- 节点是提供服务的单位,请求是发到节点上的。
- 节点接收到请求后,会对请求进行处理:
- 读请求:
- 当接受读请求,如果是根据ID来获取数据的读请求,那么它会选择有这个ID的数据的分片来获取数据(可以根据ID来判断该分片上是否有这份数据);如果是搜索类的请求,首先会根据索引表来搜索,得出相关文档的ID,然后根据ID从这