个索引的相关分片来获取数据(如果有2个pri,2个rep,那么搜索的分片可能是p1r2、p2r1、p1p2,r1r2,只要能完整地获取索引的所有数据即可)。
写请求:
- 当接收写请求,节点会选择根据ID来计算应该把这个数据存储到哪个主分片上,然后通过主分片来修改数据,主分片修改完成后,会将数据同步到副本分片上。【由于存在一个同步过程,同步完成之前,某个分片上可能不存在刚刚插入的数据,但概率较小,因为同步是极快的(NRT)】
【再次提醒,主分片有读和写的能力,副本分片只可以读,所以数据的更新都发生在主分片上】
协调节点cordination node
索引的数据是存储在节点上的,当一个请求发到节点上的时候,可能这个节点上并没有这个索引的数据,那么这个时候就需要把请求转发给另一个节点了,这时候原本的节点就是一个“协调节点”。
请求分发的负载均衡
一个索引存储在多个主分片和副本分片上,索引的数据会平均分配到每一个主分片中,然后每一个副本分片拷贝对应主分片的数据。
对于数据存储,数据是存储在分片上的,而分片位于节点上,在上面说了分片会均衡分配到每一个节点上,这样也保证了节点上的数据量是平均的。
除此之外,对于读取某一个主分片及其副本分片上的数据的时候,会使用轮询算法来将读请求平均分配(大概意思就是,假设现在对于主分片1有三个副本分片,那么总数为4,假设分别编号1、2、3、4,那么可能地,第一次请求交给了1,那么第二次请求要交给2,第三次要交给3。。。以此类推,超过4则从头开始)。
补充:
- 除了上面的内容,还有一些与集群比较相关的内容,比如某节点宕机后会发生什么。这些会留到集群管理篇再讲。
小节总结
本节简单说了一下读写操作的流程,ID类的读请求直接根据ID来查找文档,搜索类的读请求先搜索索引表,再根据ID来查找文档;写数据请求会根据ID来计算应该把这个数据存储到哪个主分片上,然后通过主分片来修改数据;最后讲了一下对于请求分发的负载均衡,一方面通过数据量的平均分配来均衡,一方面使用轮询算法来降低单个分片的处理压力。
文档的元数据
你在查询文档的时候,你可能看到返回结果中有如下的内容:
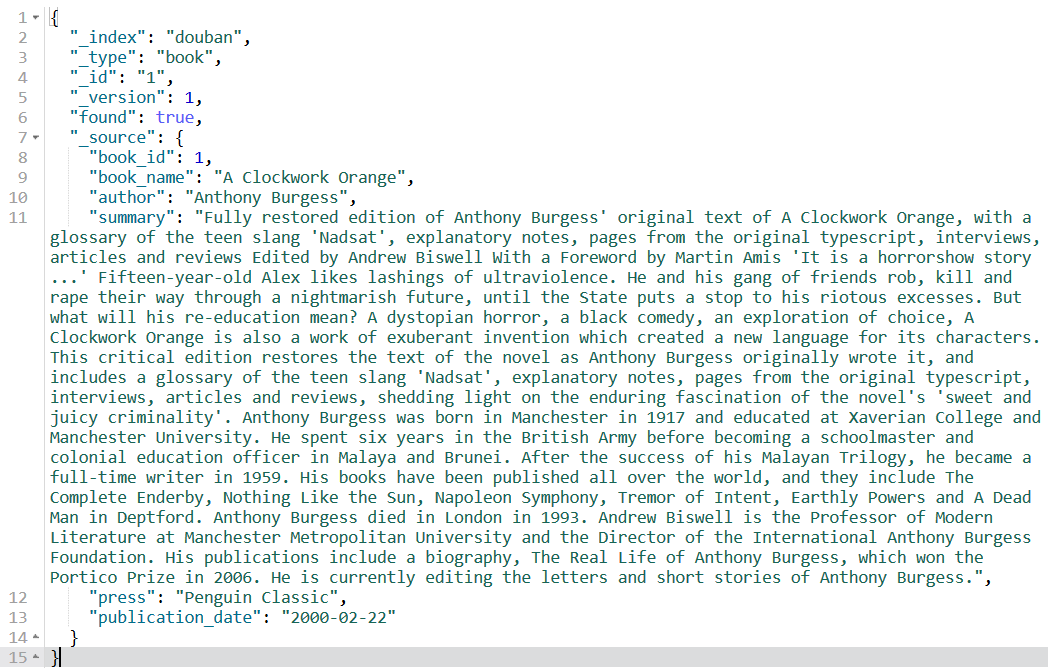
上面的几个前缀有_的就是元数据。
_index:代表当前document存放到哪个index中。_type:代表当前document存放在index的哪个type中。_id:代表document的唯一标识,与index和type一起,可以唯一标识和定位一个document。【在前面我们都是手动指定的,其实可以不手动指定,那样会随机产生要给唯一的字符串作为ID】_version:是当前document的版本,这个版本用于标识这个document的“更新次数”(新建、删除、修改都会增加版本)_source:返回的结果是查询出来的当前存储在索引中的完整的document数据。之前在搜索篇中讲到了,我们可以使用_source来指定返回docuemnt的哪些字段。
元数据与具体的文档数据无关,每一个文档都有这些数据。
文档的数据类型
对于web中的json,数据格式主要有字符串、数值、数组和{}这几种。
比如:
{
"name": "neo",
"age": 18,
"tool": ["clothes", "computer", "gun"],
"gf": {
"feature": "beauty"
}
}
ElasticSearch并不是这样的,因为它要考虑分词,就算是字符串,它也要考虑里面的数据是不是日期类型的,日期类型通常不会分词。
数据类型
ElasticSearch主要有以下这几种数据类型:
- 字符类:
- text:是存储字符串的类型,在elasticsearch中存储会分词的字符串数据一般用text
- keyword:也是存储字符串的类型,在elasticsearch中用于存储不会分词的、结构化的字符串数据
string:string在5.x之前可以使用,现在已被text和keyword取代。
- 整数类型:
- 浮点数类型:
- 日期类型:date
- 布尔类型:boolean
- 数组类型:array
- 对象类型:object
【除了上述的类型之外,还有一些例如half_float、scaled_float、binary、ip等等类型,由于不是非常基础的内容,所以这里不讲,有兴趣的可以自查。】
补充:
- 数据类型本身是没有多少重要的知识点,重要的是与数据类型紧密相关的mapping。因为mapping存储的就是索引的结构信息,下面小节将讲述mapping。
mapping
mapping负责维护index中文档的结构,包括文档的字段名、字段数据类型、分词器、字段是否进行分词等。这些属性会对我们的搜索造成影响。
dynamic mapping
在前面,其实我们都没有定义过mapping,直接就是插入数据了。其实这时候ElasticSearch会帮我们自动定义mapping,这个mapping会依据文档的数据来自动生成。
此时,如果数据是字符串的,会认为是text类型,并且默认进行分词;如果数据是日期类型类(字符串里面的数据是日期格式的),那么这个字段会认为是date类型的,是不分词的;如果数据是整数,那么这个字段会认为是long类型的数据;如果数据是小数,那么这个字段会认为是float类型的;如果是true或者false,会认为是boolean类型的。
举例:
我们插入以下数据【如果你用了这个索引,那么可以自定义一个索引,避免我随意创建的数据污染了你的测试数据】:
PUT /test/person/1
{
"name":"suke",
"age":18,
"tall":178.5,
"birthdate":"2018-01-01"
}
然后查看索引,其中mapping定义了我们刚刚定义的字段的信息:
GET /test

创建mapping
【之前在第二篇中有提到,可以通过查看索引来查看mapping】
语法:
【[]代表里面的内容是可选的,非必须的】
PUT /index/
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"type名": {
"properties": {
"字段名": {
"type": "数据类型",
// 是否索引,不索引则不将这个字段列入索引表,无法对这个字段进行搜索
[